概要
実際のシステム開発におけるAWSの活用方法を学ぶ。AWSのサービス単体を学ぶのではなく、ユースケースを元に実際のシステムにおけるAWSの活用方法を学びます。
ユースケースから学ぶAWS活用方法
AWSを使うという言葉をよく耳にします。この一言を聞いて、どういうイメージが湧くでしょうか。
著者は「AWSのどのサービスを使う?」「AWSをどのように使う?」という疑問が湧いてきます。
AWSを使うと一言で言っても、具体的な活用方法は多岐に渡ります。
AWSの歴史を振り返ると、誕生したのは2006年、当時は数えるほどのサービスしかありませんでした。
時間とともに急速に進化しており、本教材執筆時の2022年では200を超えるサービスがあります。
毎年新たなサービスが追加され、既に存在しているサービスも機能追加されたりなど進化を遂げています。
最近はインターネットで容易に情報を入手できます。一方でAWSの進化も早いため情報が断片的になりがちです。
これからAWSを学ぼうとしている人は当然ながらAWSの知識もまだ未熟です。
インターネットの情報収集に関しても、良い記事とそうでない記事を見分けるチカラも備わっていません。
AWSを学ぶ際、AWSをどのように使うかという切り口で、学習することが大切です。
本教材では、これからAWSを学ぼうとする人に向けて、 ユースケースを題材にAWSの活用方法を解説いたします。
本教材が終えたらどのような状態になっているか
下記の考え方がわかる
- AWSで新規にWebシステムを立ち上げる際の考え方
- 運用保守を意識したセキュリティ対策
- 負荷対策の方法
- テナント設計
- コストの最適化
- 障害の復旧
受講における必要条件
- AWSとは何か。クラウドとは何か。といった基礎的なことを学習した。
- AWSアカウントを作成し、AWSコンソール(管理画面)にログインしたことがある。
- 無料枠を利用してEC2やRDSを立ち上げたことがある。
この教材の対象者
- AWSの基礎を学習したが実際の活用シーンがイメージできない
- AWSサービスを選定する際のポイントが分からない
- AWSの可用性や障害耐性が理解できない人
- 実業務(実プロジェクト)でAWSを使ったことがない。
- 既にAWSで構築されたシステムの環境を触ったことはあるが、新たにAWSでシステムの環境を作ったことがない。
学ばないこと
- ハンズオン形式の教材ではありません。手を動かして学ぶことは想定しません。
- AWSアカウントの作成方法については解説しません。
- IAMユーザー、IAMロールについては解説しません。AWSアカウント作成時のルートユーザーを利用する想定です。
- 本教材ではリージョン、アベイラビリティゾーン、VPC、サブネットについては解説しません。AWSアカウント作成時はじめから存在するVPC、サブネットを利用する想定です。
本教材の対応バージョン
2022年6月時点でのAWS
学習における注意点
AWSは従量課金です。AWSアカウント登録時にクレジットカードの登録が必要です。
本教材では「考え方」を解説するため、実際のAWS構築作業は行いません。
執筆者について
Web系のフルスタックエンジニアであり、AWSソリューションアーキテクト・アソシエイトの資格を保有しています。
実務でAWS構築の経験もあり、実践的に押さえておいた方が良いポイントを知っています。
目次
0章 はじめに
本教材の概要について解説します。
1章 ユースケース-1 AWSで新規にWebサービスを立ち上げる
AWSでWebサービスを立ち上げる際のパターンを2つ紹介します。
2章 ユースケース-2 運用保守を意識したセキュリティ対策
踏み台サーバ、セキュリティグループの考え方を解説します。
3章 ユースケース-3 パフォーマンス改善
サーバのモニタリングを行う方法について解説します。
また、パフォーマンス改善対策について4パターン紹介します。
4章 ユースケース-4 テナント設計
テナント設計について2パターン紹介します。
5章 ユースケース-5 コストを最適化する
AWSでコストを意識するときの考え方について解説します。
6章 ユースケース-6 障害を復旧する
可用性と耐久性の確保について解説します。次のパートに進む
1-1ユースケースの概要1章では、AWSに新しくWebシステムを構築する場合のユースケースについて考えます。
新しくWebシステムを構築するというユースケースですが、2つあります。
- 新しく開発したシステムをAWSで稼働はじめる
- AWS以外の環境で既に稼働しているWebシステムをAWSに移行する
こういったとき、AWSをどういった構成で構築するのがよいでしょうか。
開発プロジェクトの状況を検討して決めることが大切です。
本章は、まずはじめに次のパート以降で実現パターンを2つ解説します。
- 単一サーバ構成パターン
- サービス分離構成パターン
そのあと、ユースケースに応じてどのように選択するのがよいか解説いたします。
本章で登場するAWSのサービス
本章で登場するAWSのサービスは次のとおりです。
それぞれのサービスについて概略でよいので確認しておきましょう。
本章で登場するWebアプリケーション
AWSにデプロイするWebアプリケーションについて、本教材ではサンプルアプリケーションは用意いたしません。
仮想的なWebアプリケーションを想定して解説します。
仮想的なWebシステムの構成
仮想的なWebアプリケーションは次のような構成です。
- アプリケーションは
PHP + LaravelやRuby on Railsなどの一般的なアプリケーションを想定します。 - データベースは
MySQLやPostgreSQLなどのリレーショナルデータベースを想定します。
Webシステムの機能
仮想的なWebアプリケーションには次のような機能があります。
- データベースにデータを登録・更新・削除する機能がある
- データベースからデータを参照する機能がある
- 画像ファイルのアップロード機能がある
簡単ですが、このような仮想的なWebアプリケーションをイメージしてください。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、単一サーバ構成パターンについて解説します。
単一サーバ構成パターン
はじめにご紹介するのは単一サーバ構成パターンです。
EC2を1台のみ利用し構築します。
構成図
単一サーバ構成パターンの構成イメージ図です。
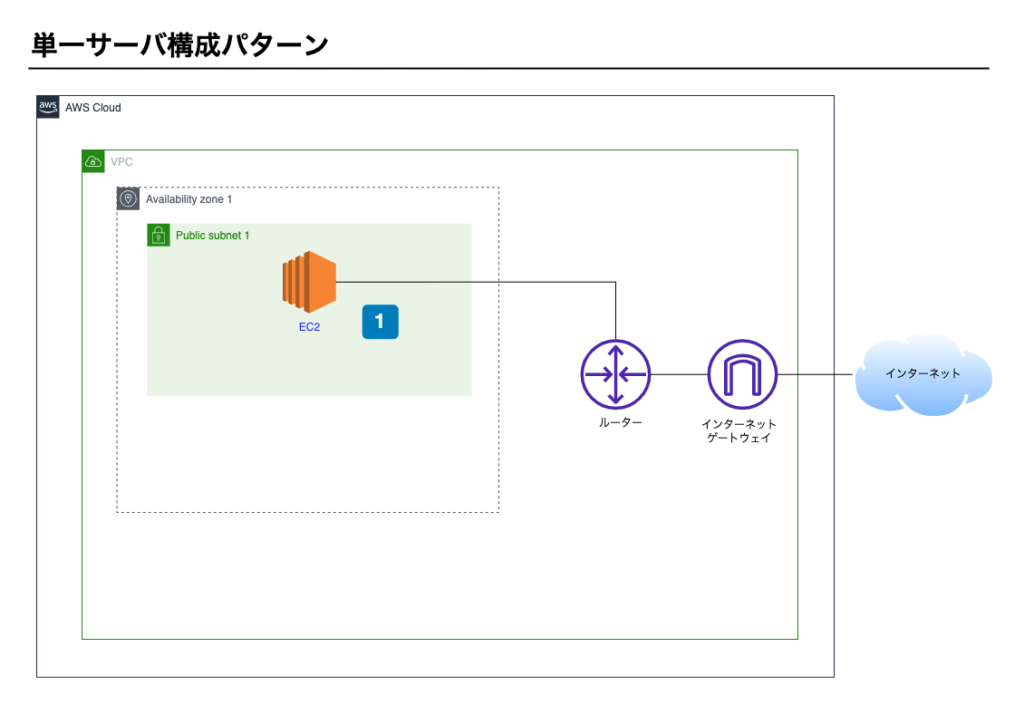
ポイント1 – EC2
- WebサーバとAPサーバがEC2にインストールされている。
- データベースがEC2にインストールされている。
- システムの利用者がアップロードした画像などがEC2内のディスクに保存されている。
本パターンの特徴
スモールスタートに最適
1台のEC2で構成するシンプルなパターンです。
AWSはスモールスタートではじめ、サーバのリソースがもっと必要になったとき拡張する考え方が大切です。
1台のEC2で構成するとAWSの恩恵を受けていないように見えますが、スタートとして単一サーバ構成ではじめることは選択肢として有効です。
料金が安い
次パートで紹介するもう1のパターン「サービス分離構成パターン」ではEC2に加え、RDSとS3サービスを利用しますのでその分の費用もかかります。
一方、単一サーバ構成パターンはEC2のみを利用しますので費用は安くなります。
RDSやS3を利用するメリットはありますがシステム開発においてコストを抑えることも重要です。
単一サーバ構成パターンで発生する課金項目を下記に記載します。
| No | 対象サービス | 課金項目 | 公式のページ |
|---|---|---|---|
| 1 | EC2 | インスタンスの起動時間 | AWS EC2 料金 |
| 2 | EC2 | データ通信量 | 同上 |
※ 概略のみ記載しております。詳しく知りたいときは公式ページを参照してください。
AWS移行のリスクが少ない
単一サーバ構成パターンはLinuxやWindowsのサーバが1台あれば構築できます。
これはAWS以外のレンタルサーバ(※1)でも実現できる構成です。
つまりAWS以外の環境で既に稼働しているシステムを同じ構成のままAWSに移行できます。
移行の際に、RDSやS3を使うようにプログラムを修正する必要もありません。
AWS以外の環境からAWSへ移行する際、移行作業の費用を抑えたい状況で有効です。
※1 さくらのVPS など
可用性が低い
単一サーバ構成パターンではデータベースや画像ファイル等もサーバ上に保存されます。
EC2にて障害発生した場合、データ損失の可能性があります。
対策として次のような工夫が必要です。
- 可用性を上げる
- 定期的にバックアップを取得しておき、容易にリカバリできるようにする。
また、バックアップする処理はスクリプトを書き定期実行するなど手動で行う必要があります。
単一サーバ構成パターンの課題
障害耐性の低さに対策する
単一サーバ構成パターンで稼働続ける場合、2つの対策は必要です。
- モニタリングを行い、システムを監視する
- バックアップの取得とリカバリ方法を確立しておく
モニタリングについては3章で解説いたします。
サービス分離構成パターンへの移行
単一サーバ構成パターンはシンプルであり、小さくはじめれる点は優れていますが、障害耐性の低さは無視できません。
長期的にシステムを稼働させる場合、サービスを分離していくことが望ましいです。
次パートで解説するサービス分離構成パターンへ移行を検討してください。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、サービス分離構成パターンについて解説します。前のパートに戻る完了して次のパートに進む
1-3
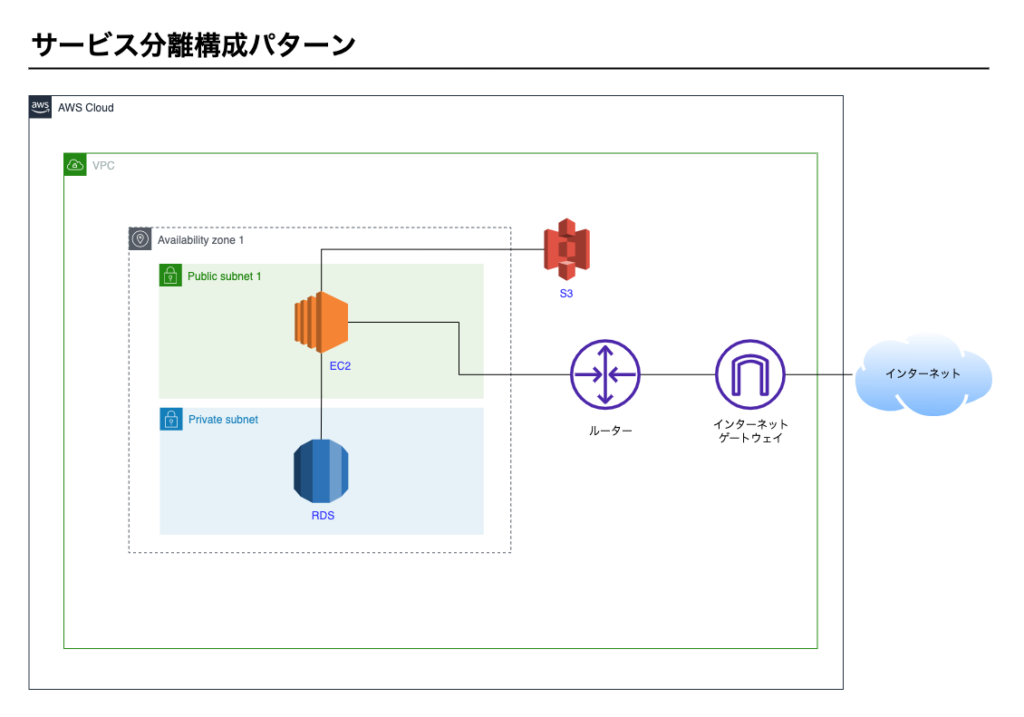
サービス分離構成パターン
次にご紹介するのはサービス分離構成パターンです。
AWSの3つのサービスを利用し構築します。
- EC2
- RDS
- S3
構成図
サービス分離構成パターンの構成イメージ図です。
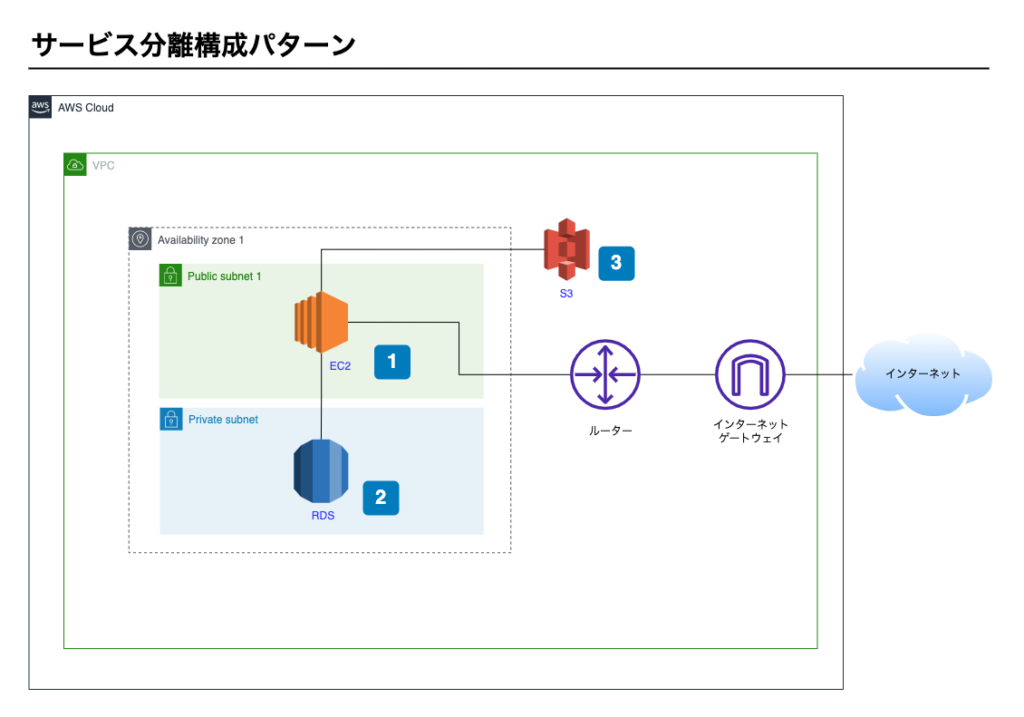
ポイント1 – EC2
- WebサーバとAPサーバがEC2にインストールされている
ポイント2 – RDS
- データベースはRDSを利用している
ポイント3 – S3
- システムの利用者がアップロードした画像などがS3に保存される
特徴
AWSでWebシステムを構築する際のスタンダードである
AWSでWebシステムを構築する際、スタンダードといってよい構成例です。
新しくシステムを開発する際、AWSで稼働することがあらかじめ決まっている場合は本パターンが有効です。
RDSやS3を利用する前提でプログラムを開発できます。
拡張性が高い
システムを運用していると負荷の問題が出て来ます。
- システム利用者が増えたことでアクセスが多くなった。
- データベースのデータが増えたことでクエリが重くなった。
などです。
こういったときは負荷対策を行います。
前パートで解説した単一サーバ構成パターンでは、1つのEC2にすべて含まれるため部分的に拡張することはできません。
しかし、サービスを分離しておくと特定のサービスのみ拡張できます。
例) RDSは1台のまま変更せず、EC2を複数台の構成に拡張してアクセス負荷を軽減させた。など。
拡張性については3章で詳しく解説します。
障害耐性が高い
前パートで解説した単一サーバ構成ではEC2に障害が発生したとき、手動でバックアップしリストアするしかありませんでした。
サービスを分離しておくと、障害が発生したサービスのみ復旧すればよくなります。
EC2に障害が発生した場合
EC2インスタンスを新たに立ち上げることで復旧できます。
環境構築が完了したEC2インスタンスのマシンイメージをスナップショットしておくことができます。
これをAMI(Amazon Machine Image)といいます。
障害発生時、新たにインスタンスを立ち上げる際、このスナップショットを利用して立ち上げることで、
環境構築が完了した状態でEC2インスタンスを作成できます。
RDSに障害が発生した場合
RDSには耐久性を上げる仕組みが備わってます。
- 自動バックアップ定期的にバックアップを取得する機能です。リストアもAWSコンソール上から行えます。単一サーバ構成パターンより安全にリストアが行えます。
- マルチAZ構成RDSをアクティブ系とスタンバイ系で2台立ち上げておき、アクティブ系で障害が発生した場合、自動的にスタンバイ系がアクティブに切り替わります。
6章で詳しく説明します。
S3に障害が発生した場合
S3に障害が発生しても保存したオブジェクトはなくならないと考えてよいでしょう。
S3の耐久性は99.999999999%です。小数点以下11個の9が並ぶためイレブンナインとも呼ばれます。
例) S3に10,000,000のオブジェクトが格納されていてるとします。内1つのオブジェクトが損失する可能性は10,000年に1度ということになります。
S3に保存したファイルはなくならないと考えてよいでしょう。
サービスを分離した分の料金が発生する
サービス分離構成パターンは、単一サーバ構成パターンに比べて料金が多く発生します。
主要な課金項目を下記に記載します。
No1とNo2は前パートで解説した単一サーバ構成パターンでも同様に料金が発生しますが、No3〜No6はサービス分離構成パターンの場合のみ発生します。
| No | 対象サービス | 課金項目 | 公式のページ |
|---|---|---|---|
| 1 | EC2 | インスタンスの起動時間 | AWS EC2 料金 |
| 2 | EC2 | データ通信量 | 同上 |
| 3 | RDS | インスタンスの起動時間 | AWS RDS 料金 |
| 4 | RDS | データベースのストレージ使用量 | 同上 |
| 5 | S3 | オブジェクトの保存容量 | AWS S3 料金 |
| 6 | S3 | 保存したオブジェクトに対するリクエスト | 同上 |
※ 概略のみ記載しております。詳しく知りたいときは公式ページを参照してください。
コスト最適化については5章で詳しく解説します。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、ユースケースに応じた選択について解説します。1-4
ユースケースに応じた選択ここまで2つの実現パターンを紹介しました。
費用を抑えるサービスを分離することで相応の費用がかかります。できる限り費用を抑えたいという要件がある場合は単一サーバ構成パターンを選択してもよいでしょう。運用保守体制が作れないシステムを構築したあとは運用保守が必要です。そのとき開発する人と運用保守する人が違う場合もあります。EC2 + RDS + S3はスタンダードな構成ですが、AWSを知らない人にとっては未知の構成です。開発する人はAWSを知っていても、運用保守する人がAWSに詳しくなければ、トラブル発生した際に対処できません。この場合は単一サーバ構成パターンからスタートし、徐々にサービスを分離していくこともよいでしょう。運用保守を担当する人のAWS教育も並行して行います。
リスクを踏まえつつサービス分離構成パターンに移行する単一サーバ構成パターンで移行してから徐々にサービスを分離するのではなくまとめて移行した方がよいと考える人もいます。選択肢としては有効ですが、システムの構成を変更する移行のため、単一サーバ構成パターンで移行するよりリスクは増えます。RDSやS3を利用するためのプログラム修正も発生するため、移行作業に関する人的要員のコストが増えます。移行時に予期せぬ問題が発生し、システムを長時間停止する可能性もあります。サービス分離構成パターンに移行する場合、そういったリスクを承知の上で取り組むことが大切です。
2-1
ユースケースの概要
1章では、AWS上に新たにWebサービスを立ち上げるユースケースについて解説しました。
2章では、運用保守を意識したセキュリティ対策について考えていきます。
1章で解説した「サービス分離構成パターン」を例に挙げてセキュリティ対策を解説します。
責任共有モデルについて
責任共有モデルとは
AWSのセキュリティは責任共有モデルを採用しています。
AWS側とAWSを利用する側で責任を共有するもので、簡単に説明すると次のとおりです。
- AWSのサービスを利用する際の責任はAWSにある
- AWS上で構築したシステムの責任は利用者にある
AWSで構築したシステムのセキュリティを考える際、責任分界点は理解しておくことが大切です。
責任共有モデルについて、詳しくは公式ページをみてください。
責任共有モデルの例
責任共有モデルの責任範囲について、例を挙げてみます。
- AWSマネージメントコンソールにて新たにEC2を立ち上げようとした際、立ち上げ中エラーが発生。これはAWS側の責任です。
- AWSマネージメントコンソールで新たにEC2を立ち上げ、長期間に渡りOSの脆弱性対策を放置した結果、その脆弱性を利用され攻撃された。これは利用者側の責任です。
脅威を理解する
情報システムのセキュリティを考える上で、脅威は大きく3つに分類できます。
- 外部からの攻撃
- 内部からの攻撃
- 外部から侵入したあとの内部からの攻撃
外部からの攻撃とは
インターネットに公開しているWebシステムは誰でもアクセスできます。
攻撃者はインターネットを経由して攻撃を仕掛けてきます。
これが外部からの攻撃です。
内部からの攻撃とは
情報システムを運用する人は、運用保守の作業を行います。
- ブラウザでAWSマネージメントコンソールを開いて作業する。
- EC2にSSHで接続して作業する。
運用する人が悪意を持つと甚大な被害が発生します。
- AWSマネージメントコンソールにて勝手にシステムを止めたり設定を変更したりする。
- AWSマネージメントコンソールでS3のデータを盗む
- EC2にSSHで接続し、RDSに接続し、データを盗む。
これが内部からの攻撃です。
外部から侵入したあとの内部からの攻撃とは
悪意をもった外部の人間が情報システムを運用する人のパソコンを乗っ取った場合です。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、外部からの攻撃に対するセキュリティ対策について解説します。
2-2
外部からの攻撃に対するセキュリティ
本パートでは外部からの攻撃に対するセキュリティ対策について解説します。
攻撃パターン
外部からの攻撃は主に2つです。
- 空いているポートへの攻撃
- http(https)ポートへの攻撃
順番に解説します。
空いているポートへの攻撃
攻撃の概要
ポートを開けることはリスクです。
攻撃者はEC2で空いているポートがないかをスキャンし、あれば攻撃をしかけてきます。
必要最低限のポートのみ開放し、不要なポートは閉じておくことが原則です。
Webシステムの場合、httpの80番ポートとhttpsの443ポートは開いておく必要があります。
対策
本攻撃に対する対策は、アクセスを拒否することです。
AWSのセキュリティグループで制御します。
セキュリティグループは次の特徴があります。
- 仮想的なファイアーウォールである。
- IPアドレスとポートを指定して通信を許可できる。
- EC2のインスタンスやRDSのインスタンスに対してアタッチする。
詳しく知りたい人は公式ページを確認してください。
前章で取り上げたサービス分離パターンを例にした、基本的なセキュリティグループです
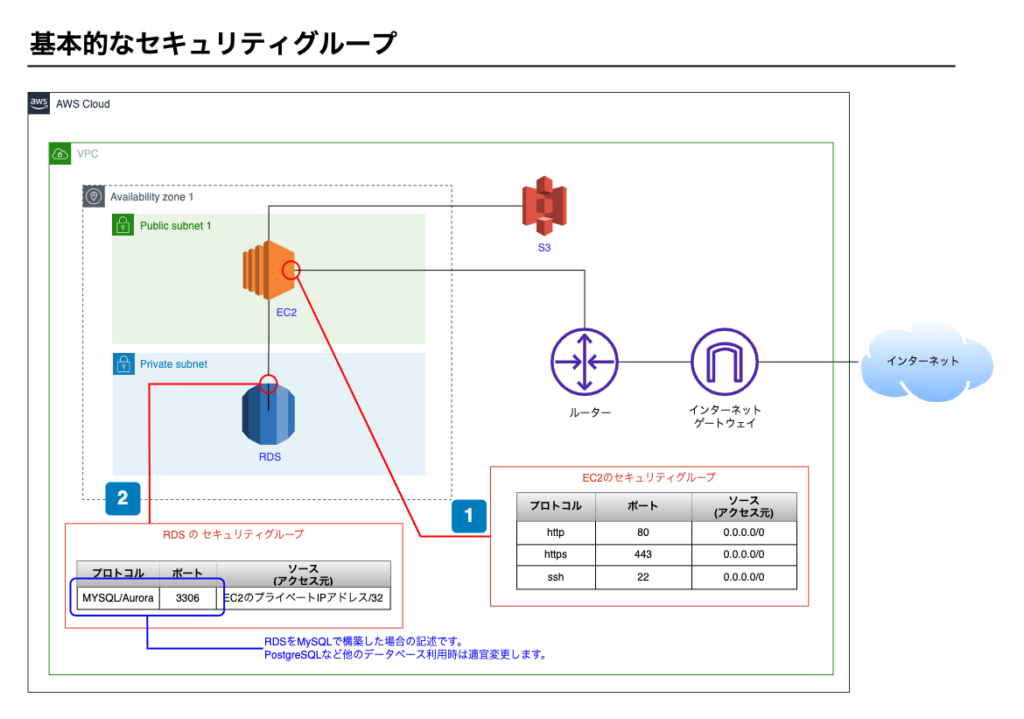
ポイント1 – EC2のセキュリティグループ
- Webシステムなので、httpとhttpsを許可します。(補足1)
- メンテナンスのためEC2にSSHで接続するため、sshを許可します。(補足2)
ポイント2 – RDSセキュリティグループ
- RDSのセキュリティグループは最低限の設定とし、厳重にします。
- MySQLの場合は3306ポートで通信するため、3306ポートのみ開放します。また、ソース(アクセス元)についてはEC2からのアクセスのみ受け付けるようにします。EC2のプライベートIPアドレス/32を指定します。
補足1 特定の組織のみに公開するようなWebシステムの場合、ソース(アクセス元)も当該組織のIPアドレスを指定し、他のIPアドレスからはアクセスを拒否します。
インターネット上すべてのアクセスを受け付ける場合のセキュリティグループ
| プロトコル | ポート範囲 | ソース |
|---|---|---|
| http | 80 | 0.0.0.0/0 |
| https | 443 | 0.0.0.0/0 |
特定の組織のみに公開するようなWebシステムの場合のセキュリティグループ
| プロトコル | ポート範囲 | ソース |
|---|---|---|
| http | 80 | 公開する組織のIPアドレス/32 |
| https | 443 | 公開する組織のIPアドレス/32 |
補足2 SSH接続するアクセス元のIPアドレスが特定できる場合、当該アクセス元からのみアクセスを受け付けるようにします
インターネット上すべてのアクセスを受け付ける場合のセキュリティグループ
| プロトコル | ポート範囲 | ソース |
|---|---|---|
| ssh | 22 | 0.0.0.0/0 |
SSH接続するアクセス元のIPアドレスが特定できる場合のセキュリティグループ
| プロトコル | ポート範囲 | ソース |
|---|---|---|
| ssh | 22 | SSH接続するアクセス元のIPアドレス/32 |
http(https)ポートへの攻撃
攻撃の概要
Webシステムの場合、httpとhttpsは開かなくてはいけません。
開いているポートについては、攻撃される前提で対策をします。
httpとhttpsに対する攻撃の例としてDos攻撃やクロスサイトスクリプティング、SQLインジェクションなどがあります。
対策
httpとhttpsに対する攻撃に対しては2つの対策が必要です。
- セキュアコーディングをする
- WAFやShieldを導入する
セキュアコーディングとは、プログラミングレベルにて対策することです。
SQLインジェクションや、クロスサイトスクリプティングなどは対策可能です。
※本教材では、プログラム上での対策方法については割愛します。
Dos攻撃は大量のアクセスを送りつける攻撃ですので、プログラミングでは対策できません。
AWSにはWAF(WebApplicationFirewall)やShieldというサービスがあります。
これらを導入することで対策できます。
詳しく知りたい方は公式ページを参照してください。
1(セキュアコーディングをする)と2(WAFやShieldを導入する)は、どちらか片方ではなく両方対応することが望ましいです。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、内部からの攻撃に対するセキュリティ対策について解説します。
2-3
内部からの攻撃に対するセキュリティ
本パートでは内部からの攻撃に対するセキュリティ対策について解説します。
攻撃パターン
内部からの攻撃は主に2つです。
- AWSマネージメントコンソール上での不正操作を行う
- EC2へSSH接続し不正操作を行う
順番に解説します。
AWSマネージメントコンソール上での不正操作を行う
攻撃の概要
運用する人はAWSマネージメントコンソールにログイン可能です。
AWSマネージメントコンソールにログインし次のような操作をします。
- AWSのシステムを停止する
- AWSの設定を変更する
- S3などのファイルを盗む
対策
対策は2つあります。
- CloudTailというサービスでAWSマネージメントコンソール上の操作履歴を記録する。通知を発生することもできる。
- AWSマネージメントコンソールのログインユーザに適切な権限を付与し、権限以上の操作を禁止する。
なお、AWSマネージメントコンソールで最上位の権限を持つ人が悪意を持った場合は止めることができません。
EC2へSSH接続し不正操作を行う
攻撃の概要
運用する人はEC2にSSH接続できます。
EC2にSSH接続し、次のような操作をします。
- RDSに接続し、データを盗む。
- ソースコードなどEC2上のファイルを盗む
- ソースコードに不正なプログラムを混入する
- ウィルスを仕込む
対策
本攻撃の対策は、SSHポートを閉じることです。
情報システムを運用する人が、EC2にSSHで接続して作業するときだけSSHポートを開放します。
SSHポートを必要なときだけ開放する手順
- AWSマネージメントコンソールにログインする。
- AWSマネージメントコンソールにて、SSH用のポートを開放する(セキュリティグループをアタッチする)
- ターミナルで踏み台ホストにSSH接続して作業を行う
- AWSマネージメントコンソールにて、SSH用のポートを閉じる(セキュリティグループをデタッチする)
- AWSマネージメントコンソールからログアウトする
しかし、必要作業があるときはEC2にSSHで接続できることに変わりありません。
そのタイミングを見計らって攻撃することも可能です。
その点を踏まえ、追加で次のような体制を築いておくことも大切です。
- どのような目的でEC2に接続するのか申請し許可を得てから接続できるようにする
- AWSマネージメントコンソールでSSH用ポートを開放する人とEC2にSSH接続する人は別とする
- EC2内で実行したコマンドの履歴を記録しておく
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、外部から侵入したあとの内部からの攻撃に対するセキュリティ対策について解説します。前のパートに戻る完了して次のパートに進む
2-4
外部から侵入したあとの内部からの攻撃に対するセキュリティ
本パートでは外部から侵入したあとの内部からの攻撃に対するセキュリティ対策について解説します。
攻撃パターン
外部から侵入したあとの内部からの攻撃は1つです。
- 運用する人のパソコンを乗っ取る。その後はEC2へSSH接続し不正操作を行う
順番に解説します。
運用する人のパソコンを乗っ取る
攻撃の概要
パソコンが簡単に乗っ取られるだろうか。と考える人もいるでしょう。
乗っ取るといっても実際はウィルスです。
- 運用する人のパソコンにウィルスを感染させる
- 攻撃者の用意したC&Cサーバがウィルスを介して不正なコマンドを実行します。
C&Cはコマンド&コントロールサーバのことです。トレンドマイクロ社の用語ページを参考として載せておきます。
乗っ取ったあとは、次の痕跡を探してAWSに不正侵入しようとします。
- 乗っ取ったパソコン内からSSH接続の鍵ファイル(.pem)を探す
- 乗っ取ったパソコン内からEC2のIPアドレスを書いたメモを探す(もしくは、保存されたSSH接続の設定を探す)
乗っ取られた場合、内部からの攻撃と同じような事態になります。
対策
本攻撃の対策は前パートと同じになりますが、SSHポートを閉じることです。
外部から侵入した攻撃者は、運用する人ではないので、運用保守するためにSSH接続するタイミング(SSHポートが開いているタイミング)がわかりません。
そのため、不正な操作をする時間帯にSSH接続はできません。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、筆者の考えをコラムとして紹介します。前のパートに戻る完了して次のパートに進む
2-5
コラム
本章の最後に、追加で解説したいトピックを1つ紹介します。
外部から侵入したあとの内部からの攻撃の深刻性について
IPAは情報セキュリティ10大脅威を毎年公表しています。
企業向け脅威と個人向け脅威が公表されてますが、企業向け脅威(2022年版)は次のとおりです。
- 左から2つの列(順位と脅威)はIPA公表によるものです。
- 残りの3列は、本章で紹介したどの攻撃に該当するか○をつけました。(筆者の見解で○をつけてます)
| 順位 | 脅威 | 外部からの攻撃 | 内部からの攻撃 | 外部から侵入したあとの内部からの攻撃 |
|---|---|---|---|---|
| 1 | ランサムウェアによる被害 | ○ | ||
| 2 | 標的型攻撃による機密情報の窃取 | ○ | ||
| 3 | サプライチェーンの弱点を悪用した攻撃 | ○ | ||
| 4 | テレワーク等のニューノーマルな働き方を狙った攻撃 | ○ | ||
| 5 | 内部不正による情報漏えい | ○ | ||
| 6 | 脆弱性対策情報の公開に伴う悪用増加 | ○ | ○ | |
| 7 | 修正プログラムの公開前を狙う攻撃(ゼロデイ攻撃) | ○ | ||
| 8 | ビジネスメール詐欺による金銭被害 | ○ | ||
| 9 | 予期せぬIT基盤の障害に伴う業務停止 | ○ | ||
| 10 | 不注意による情報漏えい等の被害 | ○ |
外部から侵入したあとの内部からの攻撃が多く、かつ順位も上位であることがわかります。
一番の脅威なのです。
前パートでも触れましたが、外部から侵入したあとの内部からの攻撃は、まずウィルスを送り込むことから攻撃が始まります。
感染方法は、不審なメールを開いたり、不審なファイルを実行したことで感染するケースがほとんどです。
注意を怠らないようにしてください。
以上で、本章は終了です。お疲れ様でした。
3-1
ユースケースの概要
AWSでシステムを運用しているとパフォーマンスの問題が生じてきます。
次のようなケースです。
- システムの利用者が増加しアクセスも増加したため、応答速度が遅くなった。
- DBのデータが増加したため、応答速度が遅くなった。
こんなときはパフォーマンス改善を行います。
しかし、どういう状況でどういう対策をするのがよいでしょうか。
3章では、パフォーマンス改善のユースケースについて考えていきます。
パフォーマンス改善の流れ
パフォーマンスに問題がなければ対策は不要です。
システムをモニタリングし、パフォーマンスの問題を検知することからパフォーマンス改善がはじまります。
その結果、見つかった問題に対策していくことになります。
次パートではモニタリングについて解説します。
さらに以降のパートでは3つの対策方法について解説します。
- スケールアップ
- スケールアウト
- RDSのリードレプリカ
本章で登場するAWSのサービス
本章で登場するAWSのサービスは次のとおりです。
それぞれのサービスについて概略でよいので確認しておきましょう。
| サービス | サービスの概要 | 公式ページ |
|---|---|---|
| CloudWatch | 監視サービス | 公式ページ |
| Auto Scaling | スケーリングサービス | 公式ページ |
| Elastic Load Balancing(ELB) | トラフィック分散サービス | 公式ページ |
| RDSリードレプリカ | 読み取り専用RDSサービス | 公式ページ |
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、モニタリングについて解説します。
3-2
モニタリング
本パートではシステムのモニタリングについて考えていきます。
モニタリングとはシステムを監視することです。
- システムへのアクセス数
- CPU使用率
- メモリ使用率
などを時系列に沿って監視します。
監視することで、システムのパフォーマンスや問題を把握できます。
例えば次のようなことがわかります。
- 20:00〜翌7:00の時間帯はアクセスが少ない。
- 13:00〜16:00の時間帯はアクセスが多く、CPU使用率がほぼ100%になっている。
CPU使用率が100%になっている時間帯はシステムのレスポンスが遅くなっている可能性があります。
更にアクセスが増えた場合、すべてのアクセスを処理できずにタイムアウトする可能性があります。
監視することで潜在する問題を発見できます。
CloudWatchとメトリクス
AWSにはCloudWatchというモニタリングのサービスがあります。
メトリクス
モニタリングをする上で、何をモニタリングするのか が重要で、「CPU使用率」などが例として挙げられます。
モニタリングした結果はAWSマネージメントコンソール上でグラフとして確認できます。
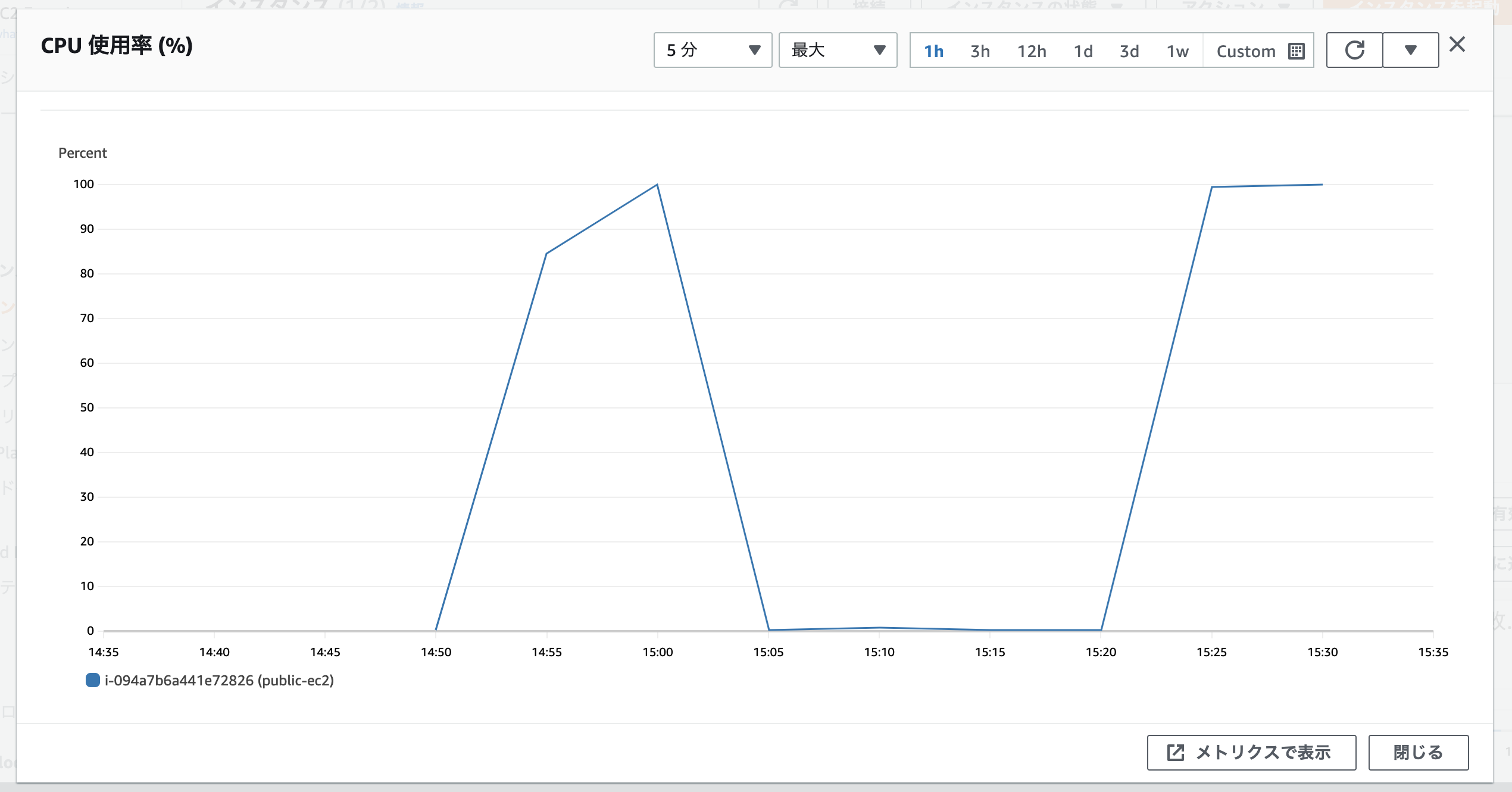
上記は新たにEC2を立ち上げ、強制的にCPU使用率を100%まで上げ下げしてみた例です。
このようにして得られるデータをメトリクスと呼びます。
この他にもCloudWatchにはたくさんのメトリクスが用意されています。
モニタリングするメトリクス
次に、どういうメトリクスをモニタリングするのかを考えます。
モニタリングをはじめる場合は次のメトリクスに注目するとよいでしょう。
- CPU使用率
- メモリ使用率
- ネットワーク使用率
- ディスクアクセス
4項目について具体的なメトリクスを挙げてみます。
| モニタリング対象の項目 | メトリクス名 | 公式ページ | 単位 |
|---|---|---|---|
| CPU使用率 | CPUUtilization | インスタンス上で使用されたCPUの比率 | パーセント |
| メモリの使用率 | mem_used_percent | 現在使用中のメモリの割合。 | パーセント |
| ネットワーク使用率 | NetworkIn | インスタンスが受信したバイトの数 | バイト |
| NetworkOut | インスタンスから送信されたバイトの数 | バイト | |
| ディスクアクセス | DiskReadOps | ディスクボリュームからの読み取り操作回数 | カウント |
| DiskWriteOps | ディスクボリュームへの書き込み操作回数 | カウント | |
| DiskReadBytes | ディスクボリュームに読み取られたバイト数 | バイト | |
| DiskWriteBytes | ディスクボリュームに書き込まれたバイト数 | バイト |
モニタリングするメトリクスの最適はシステムによって異なります。
上記メトリクスでモニタリングをはじめて、システムの特性に合わせて追加・変更するとよいでしょう。
異常の検知
CloudWatchには、メトリクスがあるしきい値を超えた場合にメールなどで通知する仕組みがあります。
これをCloudWatchアラームといいます。
CPU使用率が80%を超えた場合に通知する。といった設定です。ここだと80%がしきい値であり、自由なしきい値を設定できます。
メトリクスをモニタリングする際、アラームの設定を行うことで異常を検知できるようになります。
異常を検知したあとは対策を考えていきます。
異常検知時の分析
ここまでモニタリングの方法について解説しましたが、発生している異常に応じて対策を考えます。
問題は大きく分けて2つに分類できます。
- 処理能力のパフォーマンスに問題がある
- 入出力のパフォーマンスに問題がある
詳しくみていきましょう。
処理能力のパフォーマンスに問題がある
処理能力とはCPUやメモリの能力を指します。
- CPU処理能力が不足すると、CPUで処理待ちが発生し、レスポンスが遅くなります。
- メモリが不足すると、システムがダウンしたり、サーバー(OS)がダウンします。
CPUやメモリに関して異常を検知した場合、処理能力の問題である可能性があります。これらのケースにはスケールアップが有効です。
スケールアップについては以降のパートで解説します。
入出力のパフォーマンスに問題がある
入出力とはネットワーク通信とディスクアクセスを指します。
- ネットワーク通信量が増えると、通信が渋滞し、レスポンスが遅くなります。
- ディスクアクセスが増えると、ディスクへの読み書きが渋滞し、サーバー(OS)全体の処理が遅くなります。
ネットワークやディスクアクセスに関して異常を検知した場合、入出力の問題である可能性があります。これらのケースにはスケールアウトが有効です。
スケールアウトについては以降のパートで解説します。
有効な対策
モニタリング対象の項目毎に、異常検知した際の有効な対策を表にしました。
| モニタリング対象の項目 | メトリクス名 | 有効な対策 |
|---|---|---|
| CPU使用率 | CPUUtilization | スケールアップ |
| メモリの使用率 | mem_used_percent | スケールアップ |
| ネットワーク使用率 | NetworkIn | スケールアウト |
| NetworkOut | スケールアウト | |
| ディスクアクセス | DiskReadOps | スケールアウト |
| DiskWriteOps | スケールアウト | |
| DiskReadBytes | スケールアウト | |
| DiskWriteBytes | スケールアウト |
スケールアップ、スケールアウトについては次パート以降で解説いたします。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、スケールアップについて解説します。
3-3
スケールアップ
本パートではスケールアップについて解説します。
スケールアップとはサーバーのスペックを上げることをいい、垂直スケーリングともいいます。
具体的にはEC2インスタンスのインスタンスタイプを変更します。
構成図
スケールアップのイメージ図です。
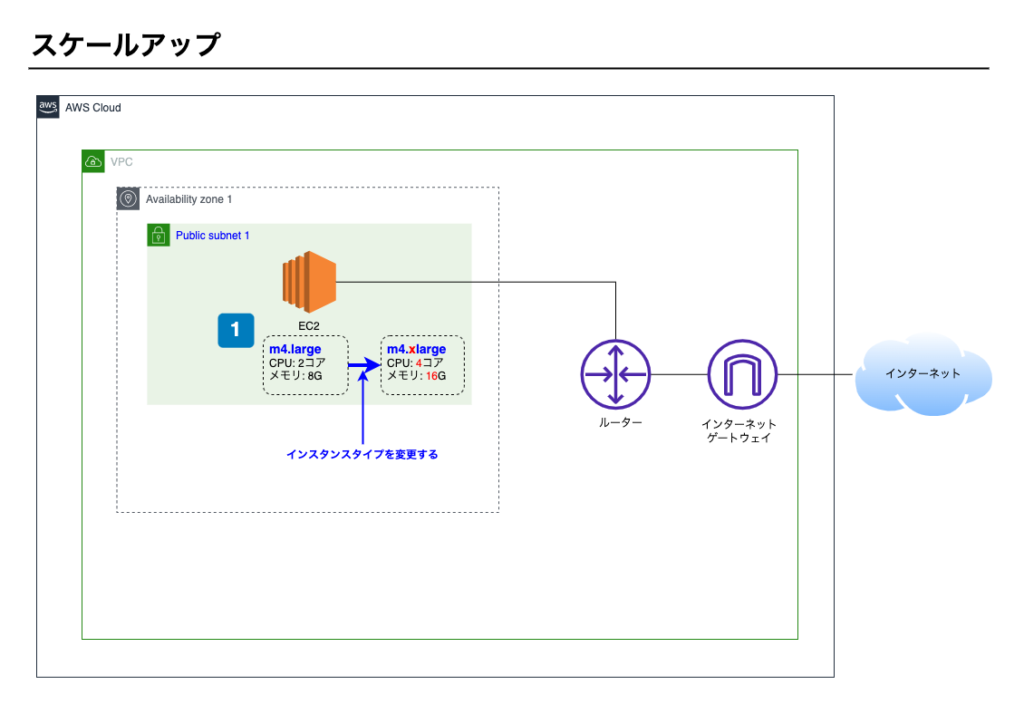
ポイント1
- EC2を別のインスタンスタイプに変更する。
インスタンスタイプ
まずはインスタンスタイプについて理解します。
インスタンスタイプとはEC2のスペックを表すもので、EC2を立ち上げる際に必ず指定します。
次のような構成になっています。
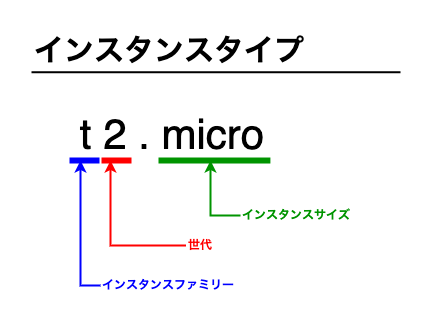
インスタンスファミリー
インスタンスファミリーは利用用途に応じて選びます。
一部を紹介します。
| 利用用途 | インスタンスファミリー | 説明 |
|---|---|---|
| 汎用 | Mシリーズ | バランスのとれたCPU、メモリ、ネットワークを備える汎用的サーバー |
| バーストパフォーマンス | Tシリーズ | 通常は負荷が少ないが突発的に負荷が上がるようなサーバー |
| コンピューティング最適化 | Cシリーズ | CPU性能が必要なサーバー |
| メモリ最適化 | Rシリーズ | 大量のメモリが必要なサーバー |
他にも様々なインスタンスファミリーがあります。詳しくは公式ページを参照してください。
世代
世代はインスタンスファミリーのバージョンです。
AWSは常に進化していますので同じインスタンスタイプでもバージョンが新しくなっていきます。
新たにWebシステムを構築する場合は、新しい世代を選んだ方がよいでしょう。
インスタンスサイズ
インスタンスサイズは性能を表します。
次のような順番で性能があがっていきます。ひとつ上がると性能は2倍になるとイメージするとよいでしょう。
- micro
- small
- medium
- large
- xlarge
- 2xlarge
戦略
インスタンスタイプを理解したところで、どういうインスタンスタイプに変更すればよいかを考えます。
スケールアップに向いているケース
処理パフォーマンスが悪い場合に向いてます。
- CPUパフォーマンスが悪い
- インスタンスサイズを上げることで改善が見込めます。
- メモリパフォーマンスは問題がなくCPUパフォーマンスのみに問題がある場合は、インスタンスタイプをCシリーズ(コンピューティング最適化)へ変更することも検討する。
- メモリパフォーマンスが悪い
- インスタンスサイズを上げることで改善が見込めます。
- CPUパフォーマンスは問題がなくメモリパフォーマンスのみに問題がある場合は、インスタンスタイプをRシリーズ(メモリ最適化)へ変更することも検討する。
- CPUパフォーマンスとメモリパフォーマンスが両方悪い
- インスタンスサイズを上げることで改善が見込めます。
スケールアップに向いていないケース
入出力パフォーマンスが悪い場合には向いていません。
処理の「待ち」が発生している状態です。入口と出口を増やして上げる必要があります。
- ネットワークパフォーマンスが悪い
- インスタンスサイズを上げることでネットワーク帯域幅が変わるためネットワークパフォーマンスは多少改善されますが、次パートで解説するスケールアウトを選択するとよいでしょう。
- ディスクアクセスが多い
- ディスクアクセスが多い場合、ディスクアクセスの上限は増えないのでスケールアップは向いていません。次パートで解説するスケールアウトを選択するとよいでしょう。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、スケールアウトについて解説します。
3-4
スケールアウト
本パートではスケールアウトについて解説します。
スケールアウトとは、複数のEC2を並列に並べて負荷分散させることをいい、水平スケーリングともいいます。
構成図
スケールアウトしない構成イメージ
スケールアウトする構成イメージ
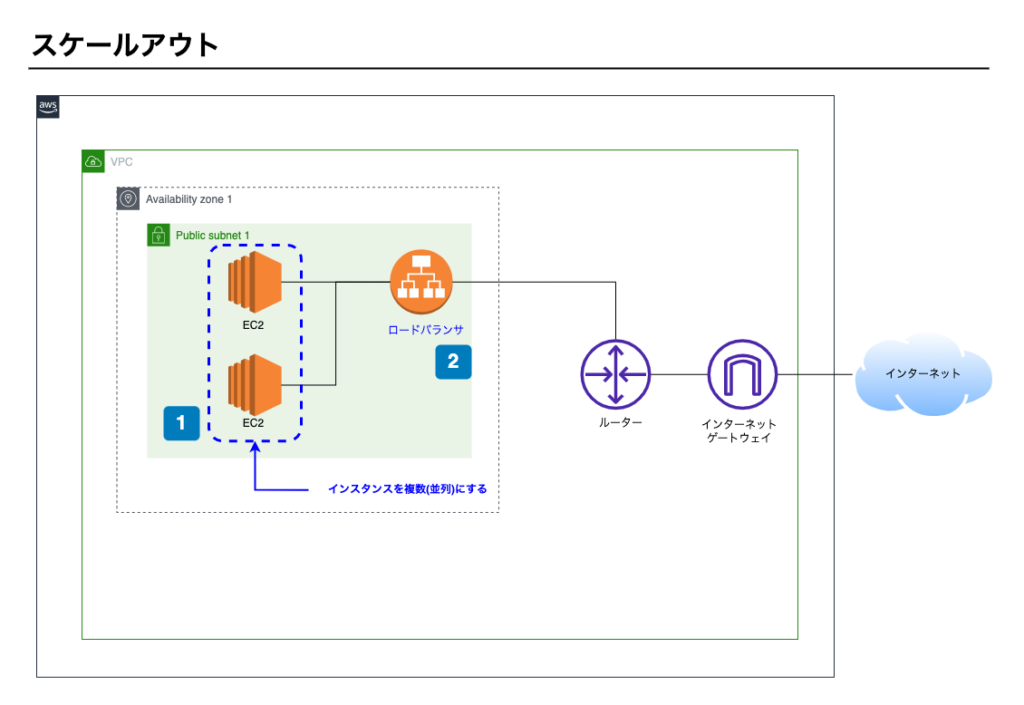
ポイント1
- EC2を複数台構成にする
- 並列に拡張する
ポイント2
- 負荷分散するためロードバランサを導入し、トラフィックを各インスタンスに分散させる。
スケールアウトの仕組み
スケールアウトには2つのサービスが必要です。
- Auto Scaling(以降、オートスケーリングと記載)
- Elastic Load Balancing(以降、ロードバランサと記載)
オートスケーリング
オートスケーリングとは
自動でEC2インスタンスを増減する機能です。
本教材3-2モニタリングでも登場したCloudWatchアラームと一緒に設定します。
アラームが異常を検知したことをきっかけとして自動でEC2インスタンスが増減します。
起動テンプレート
EC2を複数台にしますが、すべてのEC2は同じ構成でなくてはなりません。
どのEC2で処理をしても同じ結果を返す必要があるためです。
オートスケーリングが自動でEC2インスタンスを立ち上げる際の構成をテンプレートとして作成しておきます。
これを起動テンプレートといいます。オートスケーリングを設定する際、起動テンプレートを指定します。
また、起動テンプレート作成時に指定するAMIは、EC2立ち上げ後すぐに稼働出来る状態でなくてはなりません。
すぐ稼働できる状態のEC2をスナップショットで保存しておきAMIとして指定します。
構成台数
オートスケーリングでEC2インスタンスを自動で増減できますが、最小数と最大数を指定できます。
- 最小数: 負荷がない場合も最小数に指定した台数は起動した状態にする
- 最大数: 負荷が上がっても最大数に指定した台数を超えて起動はしない
ロードバランサ
複数のEC2を立ち上げても通信を分散できなければ意味がありません。
ロードバランサは通信を分散するためのサービスです。オートスケーリングとセットで構築します。
ロードバランサについて本教材では深く触れません。興味ある人は公式ページを参照ください。
戦略
オートスケーリングとロードバランサを理解したところで、どういう状況でスケールアウトが向いているか考えます。
スケールアウトに向いているケース
入出力パフォーマンスが悪い場合に向いてます。
- ネットワークパフォーマンスが悪い
- スケールアウトすることで改善が見込めます。
- アクセスに応じてスケールアウトする台数も変更できます。
- ディスクアクセスが多い
- スケールアウトすることで改善が見込めます。
- アクセスに応じてスケールアウトする台数も変更できます。
スケールアウトに向いていないケース
処理パフォーマンスが悪い場合には向いていません。
重い処理でCPUとメモリを使っているため、分散しても効果ありません。処理能力を上げる必要があります。
- CPUパフォーマンスが悪い
- スケールアウトしても、1台のEC2のCPUパフォーマンスは上がりませんので、前パートで解説したスケールアップを選択するとよいでしょう。
- メモリパフォーマンスが悪い
- スケールアウトしても、1台のEC2のメモリパフォーマンスは上がりませんので、前パートで解説したスケールアップを選択するとよいでしょう。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、RDSのリードレプリカについて解説します。前のパートに戻る完了して次のパートに進
3-5
RDSのリードレプリカ
データベースの問い合わせが増えることで、レスポンスが遅くなります。
本パートではデータベースのパフォーマンスが悪くなったときのユースケースについて考えます。
まず、WebシステムにおけるデータベースのCRUDを考えます。
- C(Create)
- R(Read)
- U(Update)
- D(Delete)
この4つの中で、一番アクセスが多くなりがちなのはR(Read)です。
Rの負担を減らすことでパフォーマンスが改善します。
本パートではRDSのリードレプリカについて解説します。
構成図
RDSリードレプリカのイメージ図です。
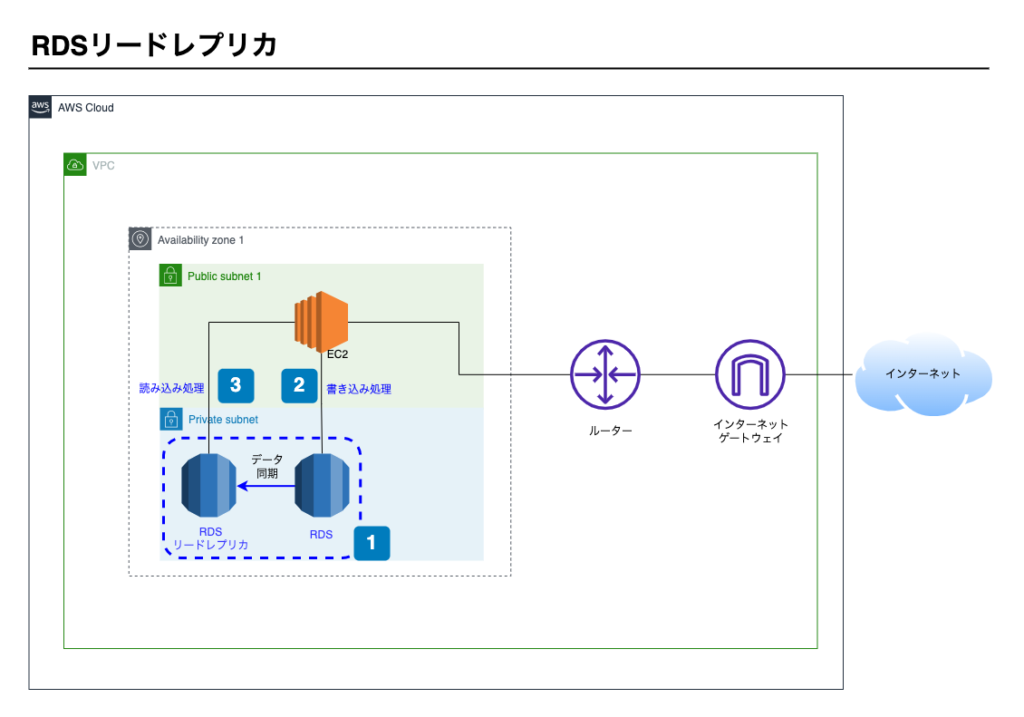
ポイント1
- リードレプリカを作成し、RDSを2台にする
- リードレプリカにデータは自動で同期される
ポイント2
- 書き込み処理は通常のRDSを参照する
ポイント3
- 読み込み処理はリードレプリカを参照する
リードレプリカ
リードレプリカとは
レプリカとは複製品のことです。リードレプリカはその名のとおり、読み込み専用のRDS複製品です。
次のような特徴があります。
- AWSマネージメントコンソール上で作成できる
- データはAWS側で自動的に同期される
- RDSの料金は2台分になる
リードレプリカの構成
リードレプリカを作成するとエンドポイントが新しく割り振られます。
エンドポイントとはデータベースのホストです。
リードレプリカを作成すると次のようになります(データベースエンジンはMySQLです)
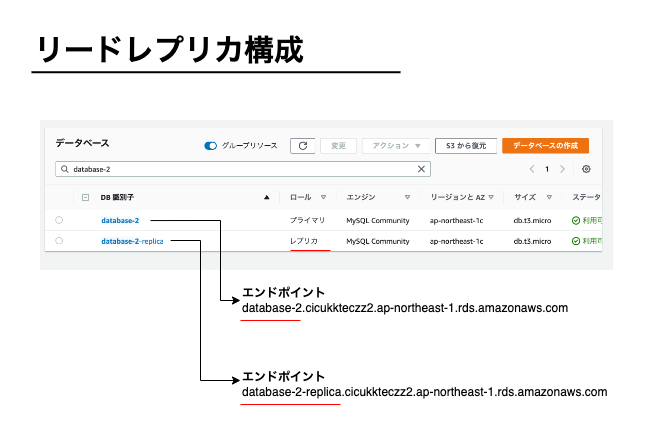
Webシステムのプログラムでは次のように使い分けます。
- 読み込み処理はリードレプリカ用のエンドポイントに接続する
- 書き込み処理は通常のRDSのエンドポイントに接続する
こうすることで、データベースに対する負荷が分散され、パフォーマンスが改善します。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、筆者の考えをコラムとして紹介します。前のパートに戻る完了して次のパートに進
3-6
コラム
本章の最後に、追加で解説したいトピックを1つ紹介します。
オンプレミスとクラウドの拡張性について
オンプレミスでインフラを構築する場合、ハードウェアの調達から行います。
パフォーマンスが悪くなってもハードウェアを買い換えることは容易でなく拡張性がありません。
そのため、将来のシステム利用者数やデータ量を予測して、最初からスペックの高いハードウェアを調達する必要があります。
クラウドは拡張性が優れているため低いスペックでインフラを構築し、利用者数やデータ量が増えるにつれて拡張していく戦略を立てることができます。
必要最低限のスペックで稼働するためモニタリングは欠かせませんが、ハードウェアの費用は大きく抑えることができます。
クラウドの拡張性は、クラウドを利用する際の大きな利点です。
以上で、本章は終了です。お疲れ様でした。
4-1
ユースケースの概要
4章ではテナント設計について考えていきます。
テナント設計が必要になる場合というのは、1つのシステムを複数の組織に提供する場合です。
イメージ図です。
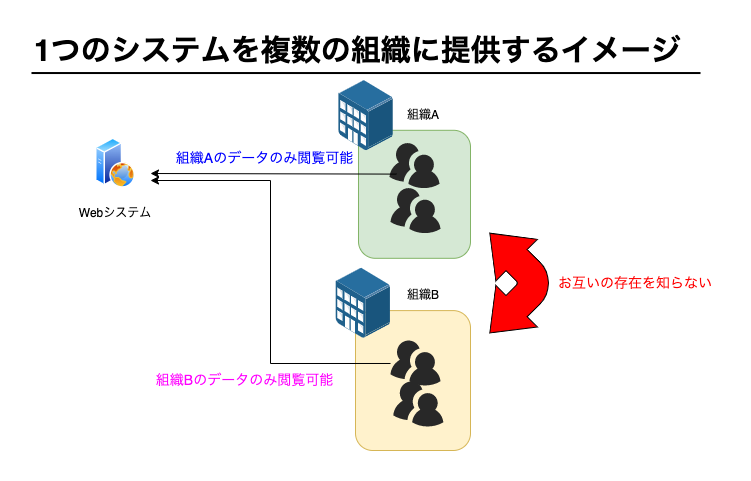
組織Aと組織Bに対して同じシステムを提供していますが、組織Aと組織Bはお互いを知りません。
システムを利用する組織は、自組織のデータのみ閲覧可能であり他組織のデータは閲覧できません。
テナント
テナントとは、システム提供側がそれぞれの組織にどういったシステム構成で提供するのかを表します。
テナントには2つのパターンがあり、組織に対してリソースを共有するのか個別に提供するのかがポイントです。
- マルチテナント – 組織間でリソースを共有する
- シングルテナント – 組織間でリソースを共有しない
それぞれについて、次パート以降で詳しく解説していきます。
リソースとは資源を表します。
コンピュータの分野においては次に挙げるものが該当します。
- CPU
- メモリ
- ネットワーク
- ディスク
本章では、複数の組織でこれらを共有するのか個別に提供するのかという点について焦点を当てます。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、マルチテナントパターンについて解説します。
4-2
マルチテナントパターン
本パートではマルチテナントパターンをご紹介します。
複数の組織を対象としたシステムを構築する際、基本となる設計です。
構成図
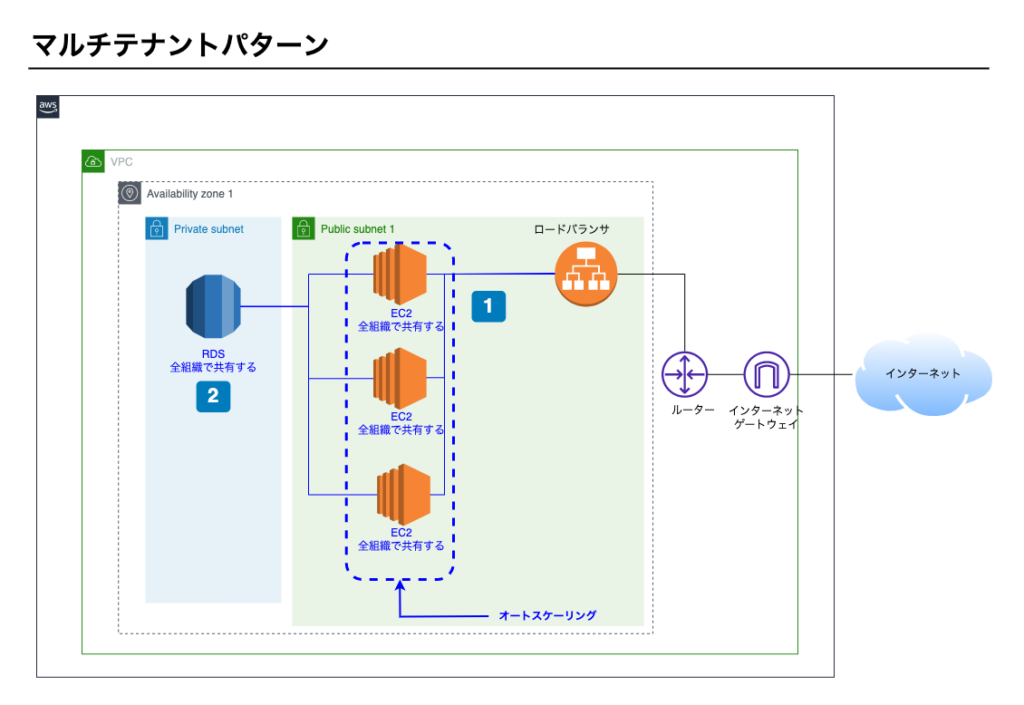
ポイント1 – ロードバランサによる負荷分散
- EC2を全組織で共有する。
- ロードバランサとオートスケーリングで負荷分散する。
ポイント2 – RDS
- RDSを全組織で共有する。
- 全組織のデータを1つのデータベースに保存する
メリット
マルチテナントには次のようなメリットがあります。
運用保守作業がシンプル
運用保守作業とは、EC2やRDSに対してメンテナンスをする作業です。
一例です。
- EC2に対するメンテナンス
- システムをアップデートする。
- OSのセキュリティパッチを適用する。
- RDSに対するメンテナンス
- システム不具合によってデータ不整合が発生し、データ修正パッチを適用する。
リソースを共有している場合はまとめて適用できます。
一方、リソースを専有している場合は個別に対応が必要になります。
マルチテナントパターンでは、全組織でリソースを共有します。
運用保守作業が必要になった際、全組織まとめて対応可能です。
AWS利用料が安い
マルチテナントパターンは組織でリソースを共有するため、利用料は最低限で済みます。
次パートで紹介するシングルテナントパターンは組織毎にリソースを専有するため、利用料は高くなります。
2つのパターンを比較すると、マルチテナントパターンは利用料が安くなります。
デメリット
マルチテナントには次のようなデメリットがあります。
リソースを共有しているため、パフォーマンスが他の組織の影響を受ける
一例を挙げます。
- 組織Aは9:00〜10:00の時間帯にアクセスが集中していた。
- 組織Bは9:00〜10:00の時間帯はシステムのレスポンスが遅く感じていた。
組織Bは組織Aのことを知りませんので組織Aで9:00〜10:00にアクセスが集中していることも知りません。
しかしリソースを共有しているため組織Aの影響を組織Bも受けてしまいます。
組織ごとにEC2とRDSのインスタンスタイプを最適化できない
次のような事例を考えます。
- 組織Aはシステムのレスポンスが遅いと感じていて、システム利用料金を上げてもよいのでパフォーマンス改善を求めています。
- 組織Bはレスポンスの遅さに不満を持っていません。システム利用料金も上げて欲しくありません。
組織Aのみを高いスペックのインスタンスタイプに変えたいところですが、リソースを共有しているため組織Aのみ対応できません。
両組織の要望を満たすことはできません。
利用シーン
マルチテナントを採用する場合は次のようなときです。
- 複数の組織にサービスを提供するが、利用する組織の数や規模が未知であり、スモールスタートではじめたい。
複数の組織を対象としたシステムを構築する場合、マルチテナントパターンを基本として考えておくとよいでしょう。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、シングルテナントパターンについて解説します
4-3
シングルテナントパターン
本パートではシングルテナントパターンをご紹介します。
シングルテナントパターンは、組織毎に構成を分けてリソースを共有しないパターンです。
構成図

ポイント1 – DNSにて組織毎の通信を分ける
- 組織毎にサブドメインを割り当て、通信を分ける。
ポイント2 – ロードバランサによる負荷分散
- EC2を組織毎に用意し専有する。
- ロードバランサとオートスケーリングで負荷分散する。
ポイント3 – RDS
- RDSを組織毎に用意し専有する。
- 組織毎のデータを1つのデータベースに保存する
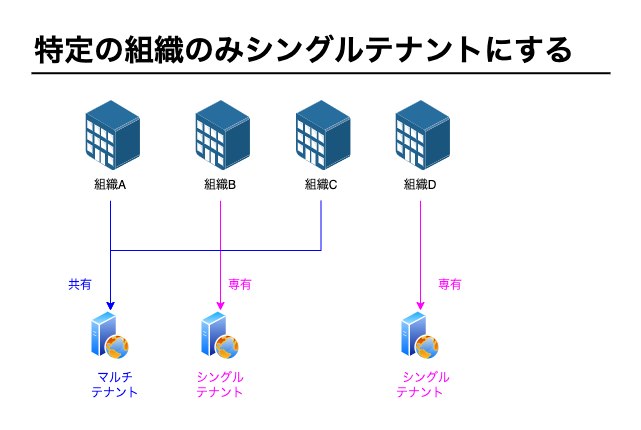
イメージ図では組織Aと組織Bの2つの組織を例にしていますが、組織の数分テナントを分けなくても構いません。
特定の組織のみシングルテナントにする構成も可能です。
例)
- 組織A -> マルチテナント(組織Cと共有)
- 組織B -> シングルテナント(組織B専有)
- 組織C -> マルチテナント(組織Aと共有)
- 組織D -> シングルテナント(組織D専有)
サブドメインとロードバランサの紐付け
サブドメインとロードバランサの紐付けはDNSサーバーにて行います。
DNSとはドメインとIPアドレスを紐付け変換する仕組みです。
紐付けと変換のイメージ図です。

本教材ではDNSについて深く解説はいたしませんが、サブドメイン毎にアクセス先を振り分けることが可能であることを理解しておきましょう。
コラム: ドメインの名前解決の流れについて
company-a.sample.comというドメインを例として、ブラウザでドメインを入力した際の名前解決の流れをご紹介します。
実際のDNSの仕組みは複雑です。筆者目線で抽象的に表現しています。
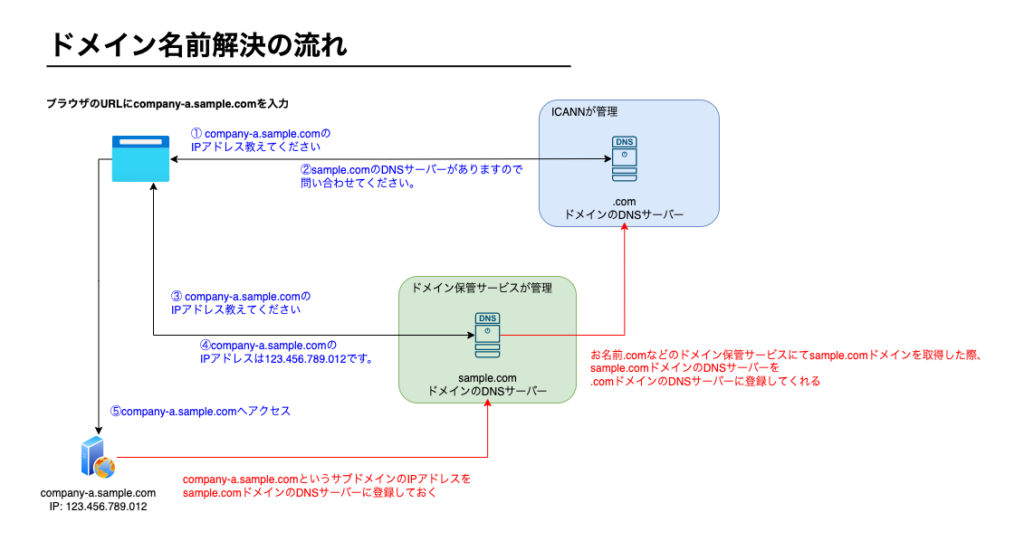
青の文字が名前解決の流れです。
赤の文字は、事前に各DNSサーバーに対して設定しておく作業です。
このようにしてドメイン名とサーバーのIPアドレスが紐づきます。
抽象化して表現しているので、詳しく知りたい人はDNSについて別途学習してみてください。
イメージ図ではAWSのRoute53というDNSサービスを利用しています
メリット
シングルテナントには次のようなメリットがあります。
リソースを専有しているため、パフォーマンスが他の組織の影響を受けない
マルチテナントではリソースの共有がデメリットでしたが、シングルテナントでは組織でリソースを専有するためメリットになります。
組織独自のカスタマイズができる
- インフラの構成が組織毎に分かれるため、組織ごとにEC2とRDSのインスタンスタイプを最適化できます。
- 組織によってインスタンスタイプを変更したり、オートスケーリングで起動するEC2の台数を変えたりできます。
- Webシステムを組織独自にカスタマイズすることも可能です。
組織が大企業の場合、システムを変更して欲しいという要望が出ることも多いです。
組織独自の機能を追加したり、デザインをカスタマイズしたり、などです。
シングルテナントならプログラムも分けることが可能ですので実現できます。
デメリット
シングルテナントには次のようなデメリットがあります。
運用保守作業が複雑
前パートで紹介したマルチテナントは運用保守作業がシンプルでありメリットでした。
一方、シングルテナントではデメリットとなります。
組織毎にリソースを専有しているため個別に対応が必要になります。
また、前述した組織毎のカスタマイズをしている場合、全組織一律で同じ対応をできない可能性もあります。
影響を調査しつつ対応が必要となり複雑です。
AWS利用料が高い
シングルテナントパターンは組織毎にリソースを専有するため、利用料は高くなります。
EC2、RDS、ロードバランサを組織毎に用意するためです。
利用シーン
シングルテナントを採用する場合は次のようなときです。
- マルチテナントからシングルテナントへの移行
- システムを利用する組織が多くなった。
- データベースのデータ量が増加し、レスポンスが遅くなった。
- Webシステムの提供プランを分けておく
- 料金プランを分けておき、プランに応じたスペックを用意する
- ログインするユーザー数が多い組織はシングルテナントにする
- 組織の要望に応える
- システムを利用する条件として、他の組織とリソースを共有しないで欲しい。という要望に応える。
- システムを独自にカスタマイズして欲しい。という要望に応える
以上で、本章は終了です。お疲れ様でした
5-1
ユースケースの概要
5章では、コスト最適化について考えます。
コストとは費用のことで、AWSのサービスを利用する料金です。
従量課金について
AWSは使用した分だけ料金が発生する従量課金です。
AWSの従量課金をイメージするために、オンプレミスとAWS(クラウド)のそれぞれについて、サーバーを用意する際の特長を考えてみます。
オンプレミス
- ハードウェアを購入する必要があり、購入時にスペックを決めておく必要がある。
- 将来の負荷を予測しスペックを決めるため、はじめから高スペックのハードウェアを使用する。
- スペックを変更できないため拡張性がない。
AWS(クラウド)
- ハードウェアを購入する必要がなく、状況に応じてスペックを変更できる。
- 最小限のスペックではじめて、負荷が上がってきたときに拡張できます。
コストの意識
AWSは従量課金のため必要最低限の費用で済みますが、それでもなお料金は抑えられた方がよいでしょう。
AWSはコストを最適化することを重要視しています。
コスト最適化は、Well-Architectedの柱の1つとして位置づけられてます。
AWSでのコスト管理サービス
ユースケースの前に、AWSでコスト管理する方法を押さえておきます。
コスト最適化のためにAWSの2つのサービスが役立ちます。
Billingサービス
AWSを利用して発生した料金をマネージメントコンソール上で確認できます。
Billingというサービスです。
Billing
Billingでは過去の請求額と次回の請求予定を確認できます。
月の途中であってもその時点の料金が確認できます。
なお、請求金額のしきい値を定めておき、予想請求額がしきい値を超えた場合に通知を受け取るようにできます。
AWSの利用者は通知を受け取った際、Billingサービスで予想を上回った原因を確認します。
コストの分析
AWSには毎月の利用状況を時系列に可視化するサービスがあります。
コストエクスプローラーというサービスです。
時系列で確認することにより、将来の予測を立てることもできます。
ユースケース
本章ではコストを抑えるユースケースとして3つ紹介いたします。
- スケジューリングしてインスタンスを立ち上げる
- 常時稼働するシステムのコスト削減
- コストを抑えたオートスケーリング
次パート以降で1つずつみていきます。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、インスタンスの起動をスケジュールするユースケースについて解説します。
5-2
インスタンスの起動をスケジュールする
本パートでは、インスタンスの起動をスケジューリングする方法について解説いたします。
システムは24時間365日、常時稼働させることが多いです。
しかし、常時稼働しなくてもよいシステムもあります。
例)
- ある組織の営業時間内のみ使用するシステム
- 月〜金のみ使用し、土日は使用しないシステム
- 月次処理のため月末に数時間のみ使用するシステム
システムを常時稼働させるかどうかは、システムの要件で定まります。
常時稼働しなくてよい要件の場合は、必要な時間帯のみEC2インスタンスを起動することでコストを抑えられます。
AWSではインスタンスの起動と停止を自動化できるため、インスタンスの起動をスケジューリングできます。
また、オートスケーリングを使用して複数台で稼働する場合、特定の時間のみインスタンス数を増減することも可能です。
例)
- ある組織の営業時間内のみ使用するシステムがあり、営業時間内は2台稼働させ、営業時間外は1台で稼働する。
EC2の自動起動・自動停止
EC2インスタンスの起動・停止の自動化が可能です。
自動化は2つのサービスで実現します。
- EventBridge
- SystemManager
EventBridge
EventBridgeは、以前Cloud Watch Eventというサービスでした。
AWSのリソースやアプリケーションからイベントを受信し、あらかじめ定義しておいたルールに従いアクションを実行するサービスです。
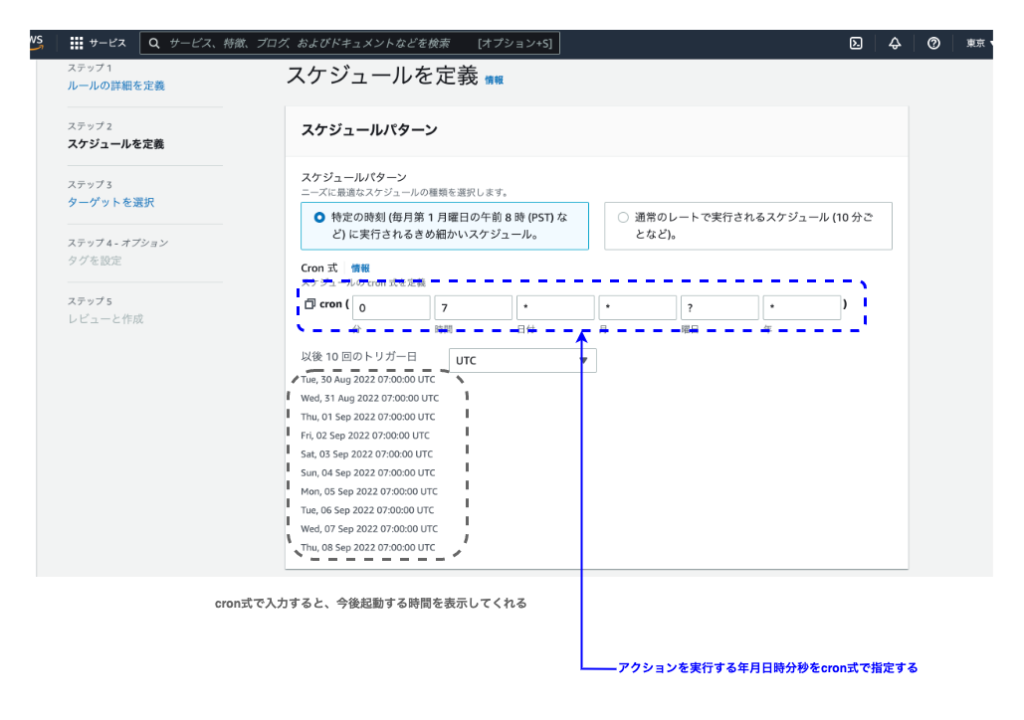
EventBridgeは特定の年月日時分秒を指定してアクションを実行することも可能です。
SystemManager
SystemMangerとはAWSのリソースに対してアクションを実行するサービスです。
EC2の自動起動・自動停止で使用するSystemMangerドキュメント(実行するアクション)
- AWS-StartEC2Instance
- AWS-StopEC2Instance
設定例
EC2インスタンスの自動起動の設定例をご紹介します。
詳細な設定手順ではなく設定の例です。本パートの大事なポイントのみ記載しています。
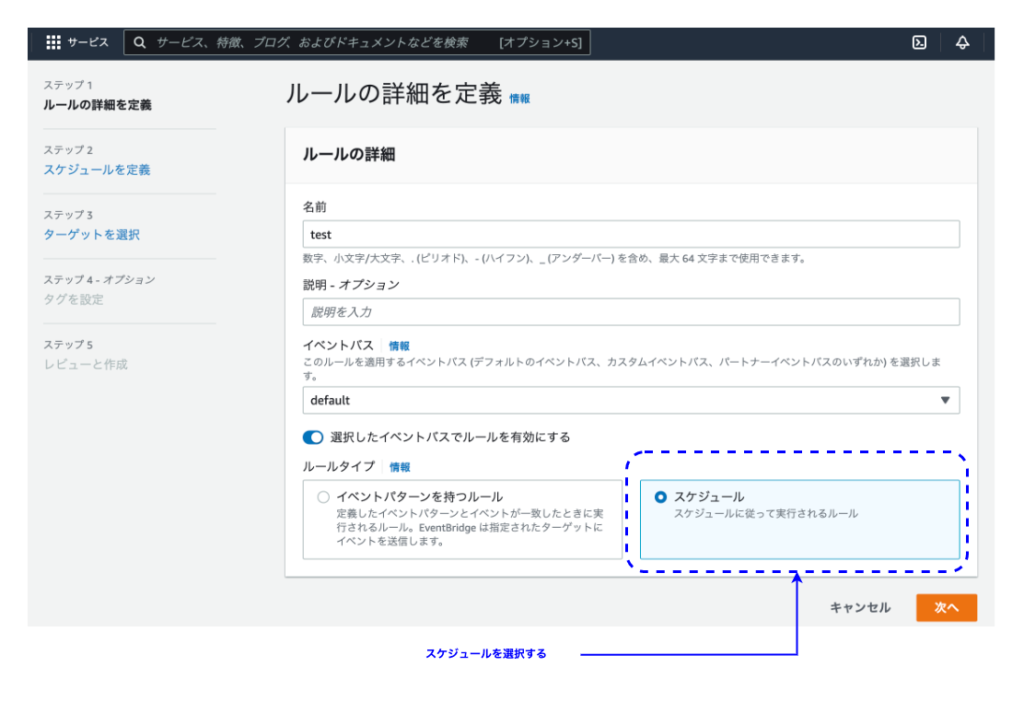
EventBridgeの画面から設定します。EventBridge > ルールを作成 を開きます。
5つのステップ(画面)で設定します。
ステップ1: ルールの詳細を定義
ステップ2: イベントパターンを構築
ステップ3: ターゲットを選択
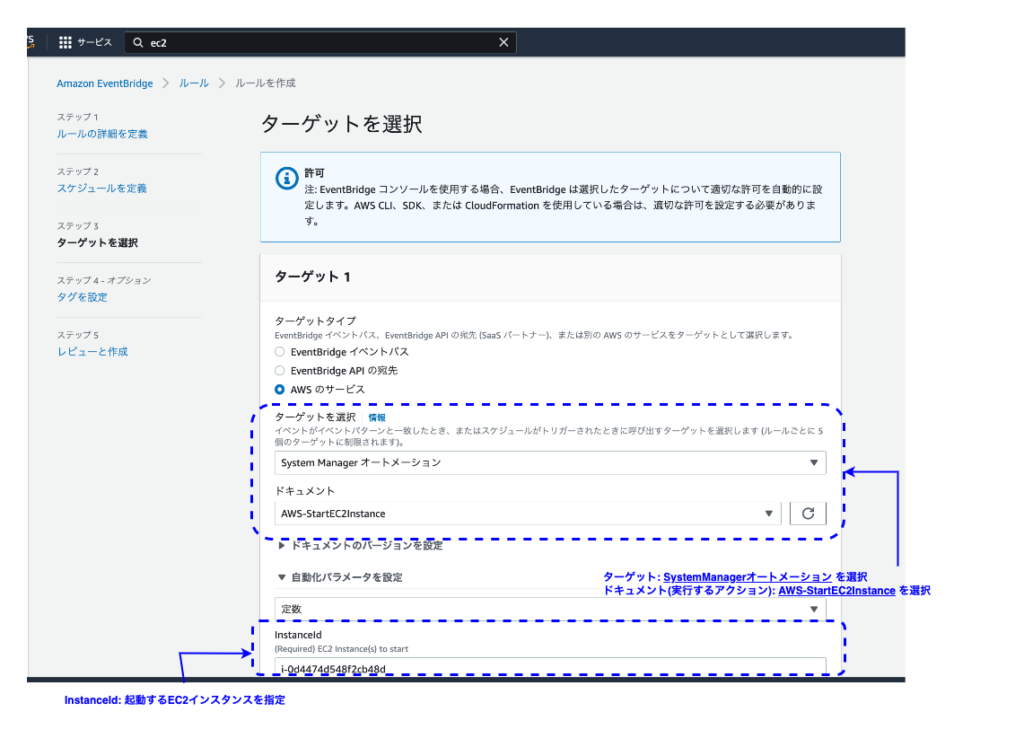
ステップ4〜5: 省略。最後まで進めてください。
この設定例は、EC2インスタンスの自動起動の設定です。
SystemManagerドキュメントにAWS-StartEC2Instanceを指定しています。
EC2インスタンスの自動停止は新たにルールを作成してください。
その際、SystemManagerドキュメントにAWS-StopEC2Instanceを指定して作成します。
オートスケーリングで特定の時間だけ起動台数を変更する
オートスケーリングにはスケジュールする機能があります。
時間帯に応じた負荷が予測できる場合、負荷が高い時間帯にEC2の起動台数を増やしたり、負荷が低い時間帯にEC2の起動台数を減らしたりできます。
完全にシステムを止めないで時間帯によってシステムのパフォーマンスを上げる事が可能です。
システムを使用しない時間があるが、システムを停止したくない場合は、当該時間帯オートスケーリングで起動台数を減らしておくとコストが削減できます。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、常時稼働するシステムのコスト削減について解説します。
5-3
常時稼働するシステムのコスト削減
前パートでは常時稼働しなくてもよいシステムのコスト最適化について考えました。
本パートは24時間365日常時稼働させるシステムのコスト最適化について解説します。
AWSは従量課金のため使った分だけ料金が発生する仕組みですが、EC2では1年間分や3年間分といった単位で事前に購入することも可能です。
事前に購入することで、最大72%の節約効果が得られます。
事前に購入する方法は2つあります。
- リザーブドインスタンス
- SavingsPlan
本パートではリザーブドインスタンスについて解説いたします。
24時間365日システムを稼働させる場合はリザーブドインスタンスの購入を検討しましょう。
本書ではSavingsPlanについて解説いたしません。
SavingsPlanは2019年にはじまったサービスです。
リザーブドインスタンスに似たように割引を受けることができるサービスとイメージしてください。
- リザーブドインスタンス: EC2インスタンスに対して割引
- SavingsPlan: EC2, Fargate, Lambdaなど柔軟に割引を適用できる
Fargate : Dockerを用いたコンテナ運用する際、EC2のコンピューティングを使用しないサービス
AWS Lambda: サーバーレスでプログラムを動かすサービス
リザーブドインスタンスとSavingsPlanの違いについて解説はいたしません。
参考記事としてClassmethod社の記事を紹介します。興味ある方はチェックしてみてください。
EC2 でリザーブドインスタンス(RI)と Savings Plans (SP)のどちらを選ぶべきか?基準とするための最強の比較表を作ってみた
リザーブドインスタンスとは
リザーブドインスタンスとは1年間または3年間継続して利用することを前提に最大72%の節約効果が得られる仕組みです。
リザーブドインスタンスの種類
リザーブドインスタンスには2種類あります。割引率も変わります。
- スタンダードリザーブドインスタンス
- インスタンスファミリーの変更が不可能
- コンバーティブルリザーブドインスタンスより割引率が高い(最大72%割引)
- コンバーティブルリザーブドインスタンス
- インスタンスファミリーの変更が可能。(※1)
- スタンダードリザーブドインスタンスより割引率が低い
※1 リザーブドインスタンス作成時の価格と同等以上のリザーブドインスタンスに限り変更可能です。
期間と支払いオプション
リザーブドインスタンスを購入する期間と支払いオプションによっても割引率が変わります。
- 期間
- 1年
- 3年
- 支払いオプション
- 前払いなし
- 一部前払い
- 全額前払
リザーブドインスタンスを利用した際のシミュレーション
次の図はスタンダードリザーブドインスタンスで実際の割引率をシミュレーションしたものです。
例とするインスタンスタイプは汎用インスタンスタイプのm5.largeです。
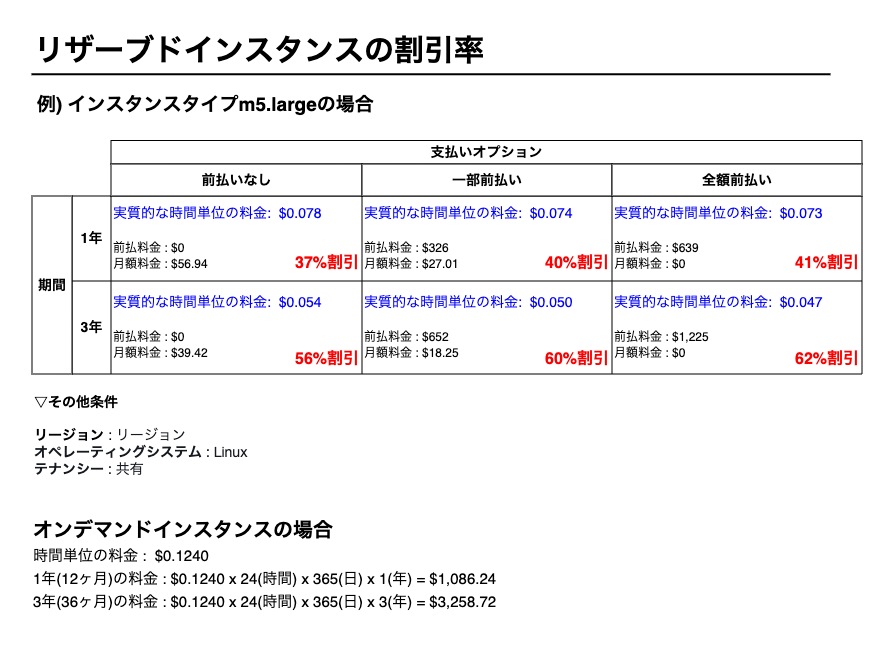
最大72%の節約と書いてますが、インスタンスタイプや契約期間、支払いオプションによって割引率は変わります。
72%の割引が得られるパターンは限られます。
最大割引率(72%)の節約が得られるインスタンスタイプはX1やX2といったメモリ最適化のインスタンスファミリーです。
例にしたm5.largeの最大割引率は62%です。
汎用のインスタンスファミリー(T4やM5など)の場合、40〜60%くらいの割引率になるとイメージしておくとよいでしょう。
掲載している金額は2022年6月時点の情報です。最新時点の情報とは異なる可能性があります。
参考
下記ページにて割引率のシミュレーションが可能です。
例として挙げたm5.largeのケース以外にもシミュレーション可能です。試してみてください。
リザーブドインスタンスの使いところ
最大割引の条件
最大の割引を受ける条件は次の3つです。
| No | 条件 | 選択肢 |
|---|---|---|
| 1 | リザーブドインスタンスの種類 | スタンダード |
| 2 | 期間 | 3年 |
| 3 | 支払いオプション | 全額前払 |
切り口を変えると、次のような状況です。
- 3年間分の料金をまとめて支払う能力がある
- 3年間インスタンスファミリーを変更せず稼働させる見込みである
世の中の変化が早い昨今、3年間の見通しを簡単には立てられません。
最大の割引率は得られなくても、状況に応じて多くの割引率を狙うとよいでしょう。
例. 期間を1年として最大限の割引を狙う
| No | 条件 | 選択肢 |
|---|---|---|
| 1 | リザーブドインスタンスの種類 | スタンダード |
| 2 | 期間 | 1年 |
| 3 | 支払いオプション | 全額前払 |
割引率: 41%
例2. 期間を3年として、インスタンスタイプを上げられるようにしておく
| No | 条件 | 選択肢 |
|---|---|---|
| 1 | リザーブドインスタンスの種類 | コンバーティブル |
| 2 | 期間 | 3年 |
| 3 | 支払いオプション | 全額前払 |
割引率: 47%
リザーブドインスタンスの導入検討
リザーブドインスタンスを導入する際、種類や期間をどのように選べばよいでしょうか。
チャートを作成してみました。
システムの特性をイメージしながら進めてみてください。
本チャートは筆者の考えに基づきます。
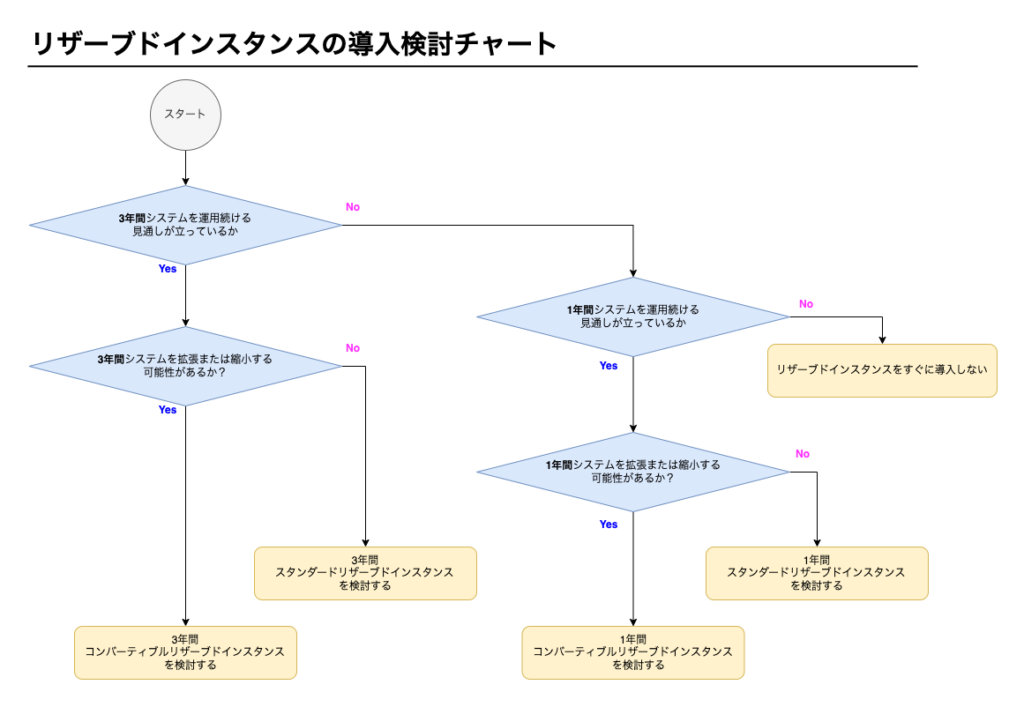
拡張・縮小する可能性があるかについて、システムの特性もありますが、利用者の増減が尺度の1つになります。
- 利用者の増減が大きい
- 前章で取り上げたような複数の組織にシステムを提供するシステム
- SNSのようなシステム
- 利用者の増減が少ない
- 企業内の業務システム
RDSのリザーブドインスタンス
リザーブドインスタンスはEC2に限らずRDSにもその機能があります。
RDSについても同じようリザーブドインスタンスを検討してもよいでしょう。
考え方はEC2と一緒です。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、コストを抑えたオートスケーリングについて解説します。
5-4
コストを抑えたオートスケーリング
本パートでは、コストを抑えたオートスケーリングについて解説します。
スポットインスタンスを活用する方法です。
スポットインスタンスとは
スポットインスタンスとはAWS内で余っているEC2の余力を活用してインスタンスを立ち上げるものです。
最大で90%の割引効果があります。
割引効果が高いですが、余力がなくなれば自動でインスタンスが停止する可能性はあります。
余力とは
我々はAWSマネージメントコンソール上でEC2インスタンスを簡単に立ち上げることができます。
インスタンスを立ち上げるとAWS内のハードウェアリソースを消費しはじめます。
AWSが用意するハードウェアに空きがなくなるとインスタンスを立ち上げることができません。
そのような自体にならないためAWS側は我々がいつでもEC2インスタンスを立ち上げられるように余力を残してます。
EC2インスタンスの余力イメージ
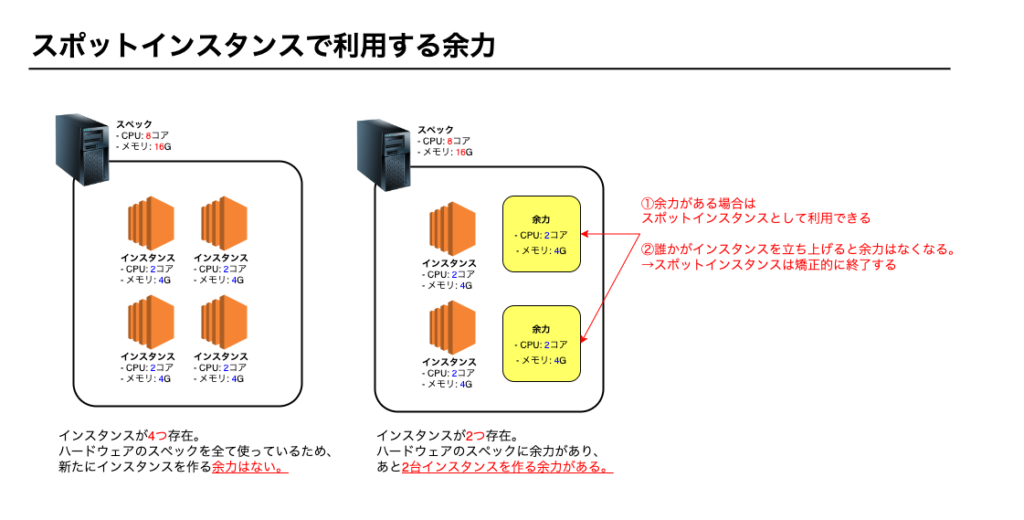
停止前に2分間の猶予がある
自動でインスタンスが停止する場合も、瞬間的に停止するのではなく停止まで2分間の猶予はあります。
インスタンス内のファイルをバックアップしたり、停止前に何かしらの処理を行いたい場合、この2分間を利用できます。
スポットインスタンスの使いところ
スポットインスタンスの使いところですが、スポットインスタンスはいつ停止してもよい前提で利用する必要があります。
スポットインスタンスが使用できなくても大きな問題にはならないが、スポットインスタンスが使えるなら使用したい。ときが使いところです。
一例
- 複数のインスタンスで処理する機械学習
- テストコードの実行
- 処理時間に制限のないバッチ処理
- オートスケーリングのパフォーマンス向上
本パートではオートスケーリングのパフォーマンス向上について解説します。
スポットインスタンスを用いたオートスケーリング
構成図
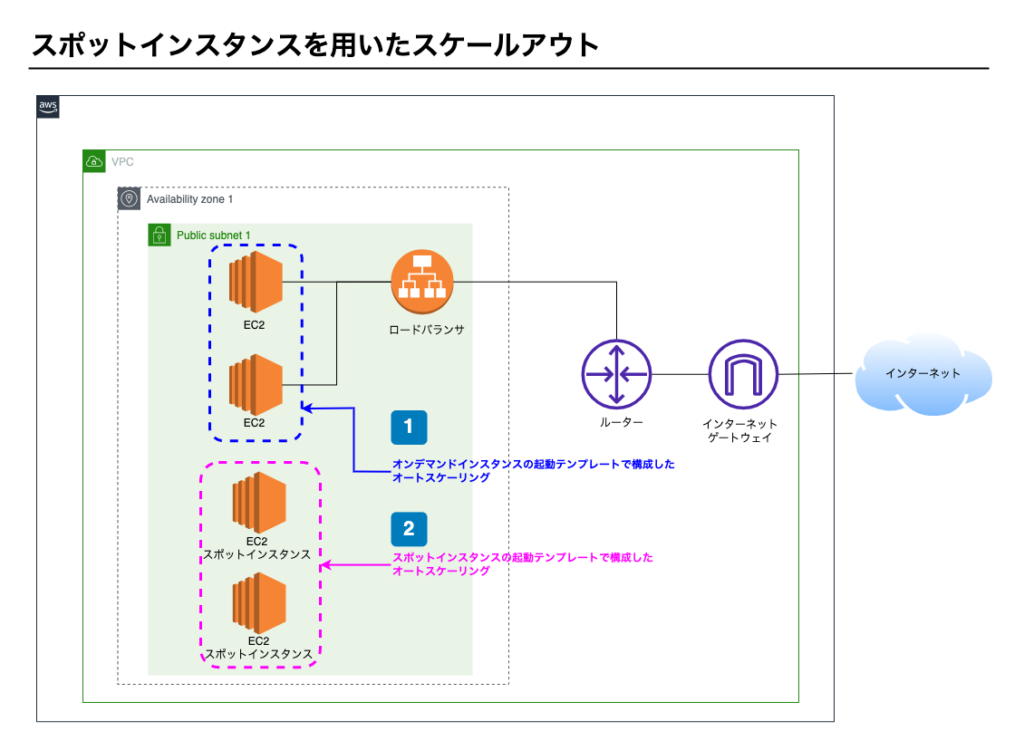
ポイント1 – オンデマンドインスタンスのオートスケーリング
- オンデマンドインスタンスで起動テンプレートをつくる
- オートスケーリングを設定し、ロードバランサに設定する
- オンデマンドインスタンスのため、自動で停止することはない
- オートスケーリングの最小起動台数も可用性を確保できる台数にする
ポイント2 – スポットインスタンスのオートスケーリング
- スポットインスタンスで起動テンプレートをつくる
- オートスケーリングを設定し、ロードバランサに設定する
- スポットインスタンスのため、自動で停止する可能性がある。
- スポットインスタンスなので最悪0台となる可能性もある。
可用性とパフォーマンス維持
スポットインスタンスのオートスケーリングだけで稼働すると、スポットが0台となったときシステムは停止します。
そのため、スポットインスタンスが0台でもシステムが稼働できるようにオンデマンドインスタンスも立ち上げます。
スポットインスタンスが立ち上がるとパフォーマンスはあがり、かつ低コストです。
こういった方法でコストを抑えることができます。
以上で、本章は終了です。お疲れ様でした。
6-1
ユースケースの概要
6章では、障害の復旧について考えます。
障害とは機能すべきものが機能しなくなることです。
障害は発生しないことが一番です。しかし誰も障害の発生を予想できません。
障害は予期せず起きるものなのです。
障害が発生する可能性を考慮し、障害が発生した際にしっかり対処することが大切です。
Design for Failureという考え方があります。
障害が発生することを前提にシステム設計を行うという考え方です。
AWSでインフラを構築する際は押さえておきましょう。
障害の種類
Webシステムで発生する障害には大きく2つに分類されます。
- インフラの障害
- Webアプリケーションの障害
インフラの障害
ハードウェアの障害です。次のような例が挙げられます。
- CPUが動作しない
- メモリが動作しない
- ディスに対してに読み込み(書き込み)エラーが発生した。
- ネットワークが遮断された
Webアプリケーションの障害
Webアプリケーション内の障害です。次のような例が挙げられます。
- プログラムのバグによりシステムエラーが発生した
- 個人情報など公開してはいけない情報が閲覧できる状態になっていた
- 高負荷のプログラムがCPUとメモリを使い切って、他のプログラムが処理できずタイムアウトした。
AWSの障害はインフラの障害に分類されます。
本教材はAWSに焦点を当てておりますのでWebアプリケーションの障害については割愛いたします。
AWSで発生する障害
さて、実際にAWSで障害が起きる場合、どのような障害が発生するから4段階で考えてみます。
- リージョン1つがすべて機能しなくなった
- アベイラビリティゾーン1つがすべて機能しなくなった
- EC2インスタンスが1台機能しなくなった
- RDSインスタンスが1台機能しなくなった
上に書いてある方が大規模障害、下に進むにつれて小規模障害です。
1と2は大規模障害、3と4は日常的に起こり得る障害といえます。
過去の事例として、2019年8月23日に東京リージョンで大規模障害が発生しました。
東京リージョンにおける1つのAZ(アベイラビリティゾーン)でEC2やRDSなどが6時間程度機能しませんでした。
この規模の障害は数年に一度起こるかどうかといった障害です。
しかし、AWSが機能しなくなれば、AWS上で稼働するシステムも機能しなくなります。
AWS上でシステムを稼働させていたサービス提供者はサービスを提供できない状態になりました。
この障害を機に、障害対策を改めたサービス提供者も多いでしょう。
本章で対象とするユースケース
本章では小規模障害について考えます。上記の3と4のケースです。
- RDSインスタンスが1台機能しなくなった
- EC2インスタンスが1台機能しなくなった
この2ケースが発生した場合について
- 障害の復旧方法
- 障害の耐久性を確保する方法
をご紹介します。
なお、大規模障害の対策について本教材では解説しません。本章最後のコラムで簡単に紹介します。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、障害の復旧方法について解説します。
6-2
障害を復旧する
本パートでは障害発生時の復旧方法について考えていきます。
考えるケースは次の2つです。
- EC2インスタンスが1台機能しなくなった
- RDSインスタンスが1台機能しなくなった
1-3にて紹介したサービス分離構成パターンで障害が発生したと仮定して話を進めます。
1-3で紹介したサービス分離構成図
EC2インスタンスの復旧
EC2インスタンスが停止したケースを考えます。
AWSマネージメントコンソール上でEC2インスタンスが停止している状態です。
イメージ図です。
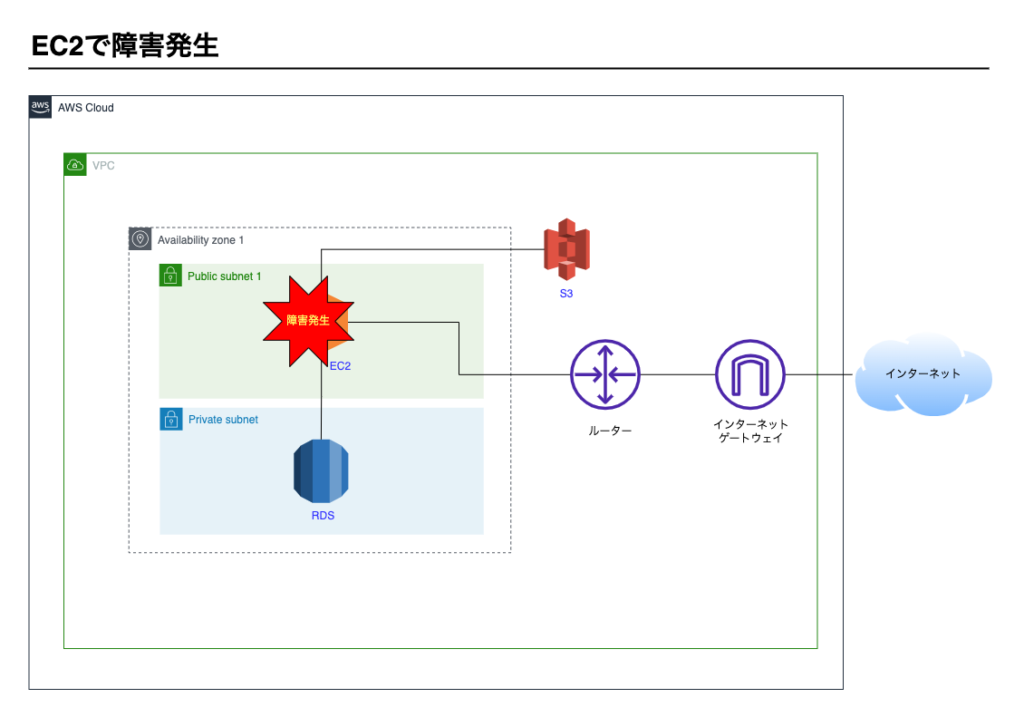
インスタンスの再起動
まず必要な作業はインスタンスの再起動です。再起動で復旧する場合も多いです。
復旧の流れは次のとおりです。
- マネージメントコンソール上でEC2インスタンスを起動します。
- 起動後、Webアプリケーション(Webサーバー、APサーバー)が正常に動作することを確認します。
- モニタリングやログなどから障害の原因を調査する。
- 障害を報告する
EC2インスタンスは起動しているが、Webアプリケーションは開けず、EC2にSSH接続もできない現象が起こることもあります。
この場合もEC2インスタンスは機能していない状態なので障害といえます。
再起動することで復旧する可能性があります。
ただし、この現象はEC2で稼働するWebアプリケーションのスペック不足や、インスタンス内でメモリリークがおきている可能性があります。
単にインフラだけの問題ではありませんので障害の原因を調査する際はWebアプリケーション側の問題である可能性も含めて調査するとよいでしょう。
EC2インスタンスの自動復旧
EC2には障害発生時に、自動でインスタンスを復旧する仕組みがあります。
自動復旧はデフォルトで有効で、マネージメントコンソール上で有効/無効を切り替えることができます。
特段理由が無い限り有効にしておきましょう。
なお、自動復旧はEC2インスタンスを立ち上げるところまでです。
Webアプリケーション(Webサーバー、APサーバー)を立ち上げはしてくれません。
EC2インスタンス立ち上げ時にシェルスクリプトを実行する仕組みがあります。
ユーザーデータにWebアプリケーション(Webサーバー、APサーバー)を立ち上げる設定をしておくとよいでしょう。
再起動できない場合
マネージメントコンソールからEC2インスタンスが起動出来ない場合もあります。
この場合、新たにEC2インスタンスを立ち上げる必要があります。
すぐにWebアプリケーションを動かせる状態のAMIがつくってあればそのAMIを元に新たに立ち上げます。
再起動出来ない場合、インスタンス内のデータを復旧できない可能性があります。
- ファイルアップロードした画像データ
- 各種ログファイル
などです。
画像データはEC2インスタンス内で保存せずS3に保存しておくことで対策できます。
本パートで例としているサービス分離構成では画像データはEC2インスタンス内で保存せずS3に保存しておくことになっていましたので、アップロードした画像が失われることはありません。
対策済の状態です。
また、ログファイルは定期的にS3に退避しておくことで対策できます。
CloudWatchLogsサービスでログを収集する方法があります。
RDSインスタンスの復旧
RDSインスタンスが停止するケースを考えます。
AWSマネージメントコンソール上でRDSインスタンスが停止している状態です。
イメージ図です。
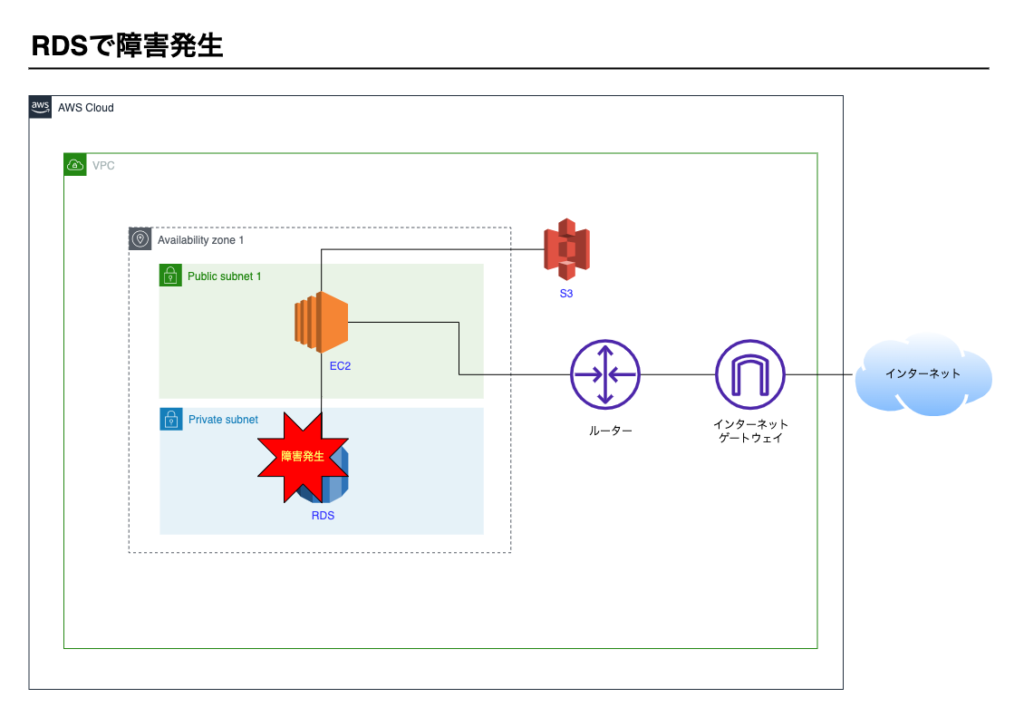
インスタンスの再起動
まず必要な作業はインスタンスの再起動です。再起動で復旧する場合も多いです。
復旧の流れは次のとおりです。
- マネージメントコンソール上でRDSインスタンスを起動します。
- 起動後、Webアプリケーション(Webサーバー、APサーバー)からRDSに接続できることを確認します。
- モニタリングやログなどから障害の原因を調査する。
- 障害を報告する
再起動できない場合
マネージメントコンソールからRDSインスタンスが起動出来ない場合もあります。
この場合、新たにRDSインスタンスを立ち上げる必要があります。
新たなインスタンスなのでデータはありません。
RDSには自動バックアップ機能がありますのでバックアップを元にデータを復旧できます。
しかし、最新のバックアップ取得時点までしか復旧できず、最新のバックアップ取得〜RDS停止時間までのデータは失われてしまいます。
新たにRDSインスタンスを立ち上げたことでRDSのエンドポイント(ホスト名)も変わります。
Webアプリケーション側でRDSの接続情報も更新する必要があります。
障害復旧の課題
障害の復旧について考えましたが、3つの課題が見つかりました。
- システムを利用できない時間が発生してしまう。
- 障害を検知後、マネージメントコンソールを操作するといった手動作業が発生する
- データやファイルを失う可能性がある。
次パートではこの課題を解決する方法をご紹介します。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、耐久性の確保について解説します。
6-3
耐久性を確保する
前パートでは障害の復旧について考えましたが、次のような課題がありました。
- システムを利用できない時間が発生してしまう。
- 障害を検知後、マネージメントコンソールを操作するといった手動作業が発生する
- データやファイルを失う可能性がある。
本パートではこれらの課題を解決する方法を紹介します。
可用性・耐障害性・耐久性
3つの課題を解決する上で
- 可用性
- 耐障害性
- 耐久性
について整理しておきましょう。
可用性とは
可用性とは、システムが稼働し続ける割合です。
システムの要件として次のように可用性を定義したりします。
24時間365日常時稼働し、可用性は99.9%とする
24時間365日の中で99.9%に該当する時間はシステムが稼働し利用できる状態を維持する。
違う表現をすると、24時間365日の中でシステムが停止する時間を0.1%(100% – 99.9%)以内に収める。
といえます。
24時間365日の0.1%は8.76(時間)です。
可用性が高いほどインフラ構成も複雑になります。
構築に伴う費用が発生しますし、AWSの運用費用もかかります。
求められる可用性の高さはシステムの特性にもよって異なりますので、可用性と費用はトレードオフの関係にあります。
可用性でよく登場する指標として 99% や 99.999% もあります。
24時間365日稼働するシステムで、停止することが許容される時間を表にしてみます。
| 可用性 | 年間で停止を許容する時間 |
|---|---|
| 99% | 87.6(時間) |
| 99.9% | 8.76(時間) |
| 99.999% | 5.26(分) |
可用性99%の87.6時間は日数に換算すると3〜4日です。99%は決して可用性が高いとはいえません。
Twitter、Facebook、YoutubeなどのSNSが数時間サービス停止した場面をイメージしてみてください。
数時間サービスが停止すればニュースになります。年間で87.6時間停止することはイメージしにくいでしょう。
一方で、99.999%の5.26(分)はかなり可用性が高いといえます。
銀行ATMや通信回線などは、このレベルの可用性を維持しています。
数時間に渡り銀行ATMを使えない障害が発生した場合、社会に及ぼす影響は甚大です。
耐障害性とは
耐障害性とは、障害が起こった際に自動で復旧する能力です。
自動で復旧できる場合、耐障害性があるといいます。
耐障害性は割合で測るものではなく単一障害点を排除できると耐障害性があがります。
単一障害点の排除とは
システム全体の中で一箇所が動作しなくなった場合にシステム全体が動作しなくなる箇所を単一障害点といいます。
1-3サービス分離構成でEC2が壊れた場合、システムは動作しません。
この状態だとEC2が単一障害点です。
このとき、オートスケーリングでEC2が複数台構成になっていれば1台のEC2で障害が発生してもシステムは継続できます。
単一障害点を排除できたことになります。
耐久性とは
耐久性とは障害発生時にデータやファイルを失わない割合です。
耐久性100%は損失ゼロを意味します。
S3やRDSはファイルやデータを保存します。そのため耐久性を上げるための仕組みも提供されます。
S3は元々耐久性が高く作られています。
1-3でも解説しましたが、S3の耐久性は99.999999999%ですのでS3に保存したファイルはなくならないと考えてよいでしょう。
RDSについても耐久性を上げる仕組みがあります。このあとマルチAZを紹介いたします。
EC2の対策
3-4.スケールアウトで紹介したオートスケーリングが有効です。
オートスケーリングによる復旧の流れ
オートスケーリングによる復旧の流れを図に沿ってみていきます。
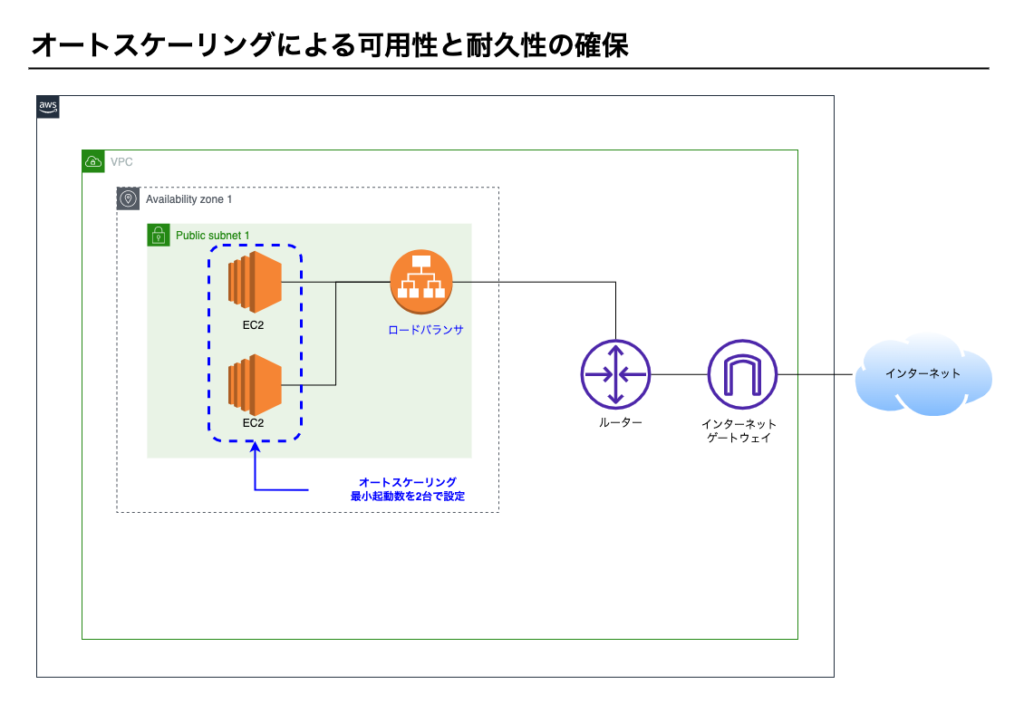
①オートスケーリングの構成
オートスケーリングにて最小起動数が2台で設定してあります。常時2台起動しています。
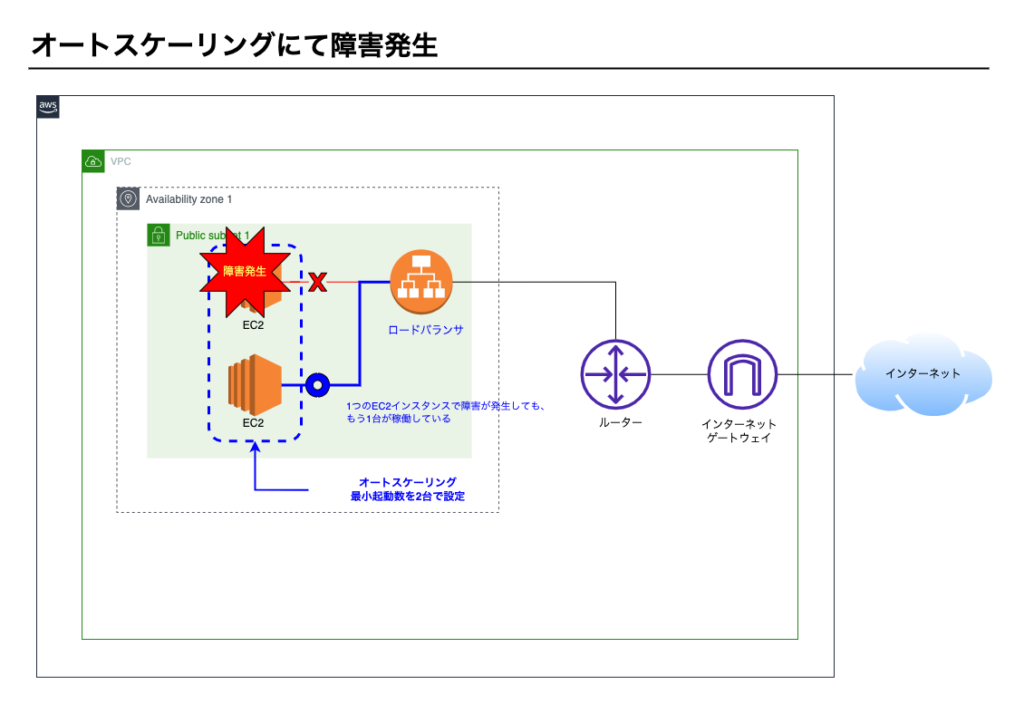
②EC2インスタンスで障害発生
1台のEC2インスタンスで障害が発生しても、もう1台のEC2インスタンスが稼働しているのでシステムは停止しません。
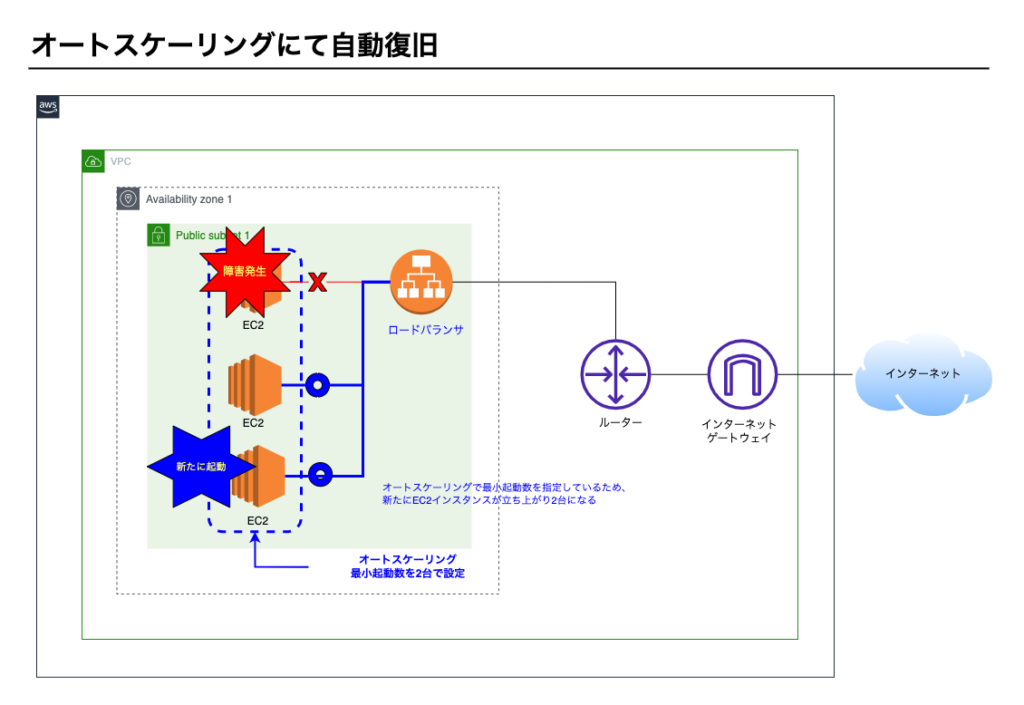
③オートスケーリングで障害復旧
オートスケーリングにて最小起動数が2台で設定してありますので、新たにEC2インスタンスが起動し、2台構成になります。
3つの課題の解決
課題1. システムを利用できない時間が発生してしまう。
最小起動数を2以上にすれば最低1台はEC2インスタンスが稼働するのでシステムは停止しない。
ただし、最小起動数を1にした場合、当該1台で障害が発生した場合、稼働するEC2インスタンスは0台になります。すぐに新たなEC2が1台立ち上がりますが、その間システムは停止します。
課題2. 障害を検知後、マネージメントコンソールを操作するといった手動作業が発生する
EC2インスタンスは自動で起動するため手動作業は不要
課題3. データやファイルを失う可能性がある。
前パートでも触れましたが、ファイルやログをS3に保存することでファイルは失われない
これにてEC2の耐久性が確保できました。
RDSの対策
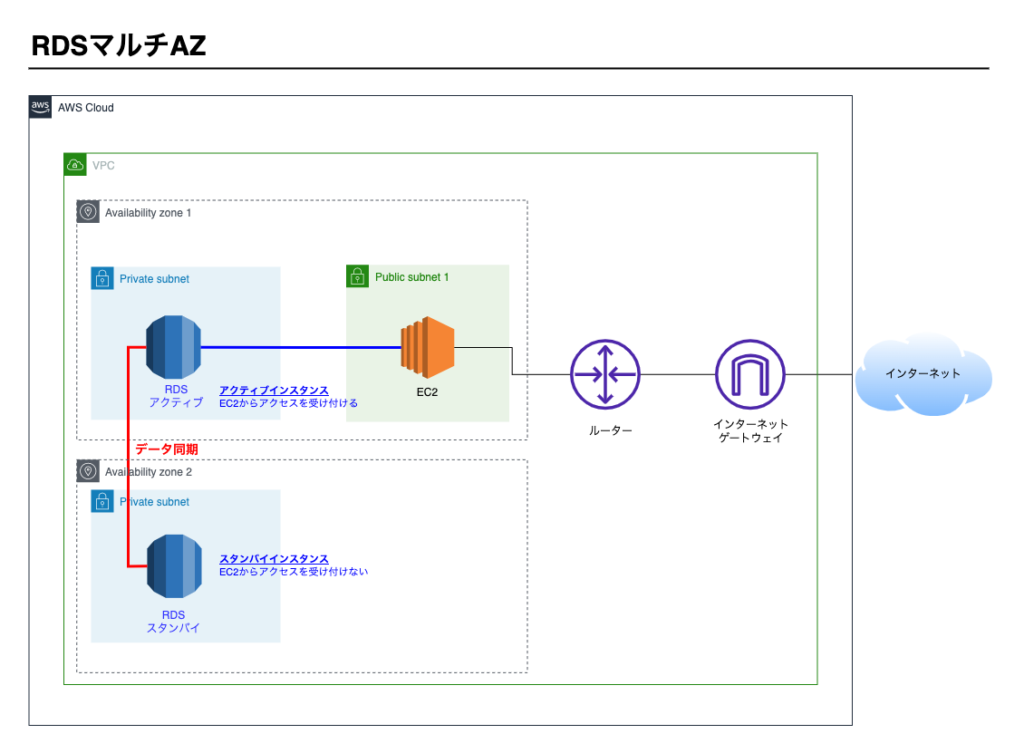
RDSにはマルチAZという仕組みがあり有効です。
マルチAZは次の特長を持ちます。
- RDSインスタンスが複数になる
- データは同期される
- アクティブインスタンスに障害が発生した場合は、自動的にスタンバイインスタンスがアクティブに切り替わる
マルチAZによる復旧の流れ
①マルチAZの構成
マルチAZ構成にすると別々のAZにそれぞれインスタンスが立ち上がる。
片方がアクティブインスタンスとなり、もう片方はスタンバイインスタンスとなる。
EC2からのアクセスはアクティブインスタンスのみ受け付けます。
②アクティブインスタンスで障害発生
アクティブインスタンスで障害が発生すると、AWSが自動で障害を検知し、スタンバイインスタンスをアクティブに切り替え始める。
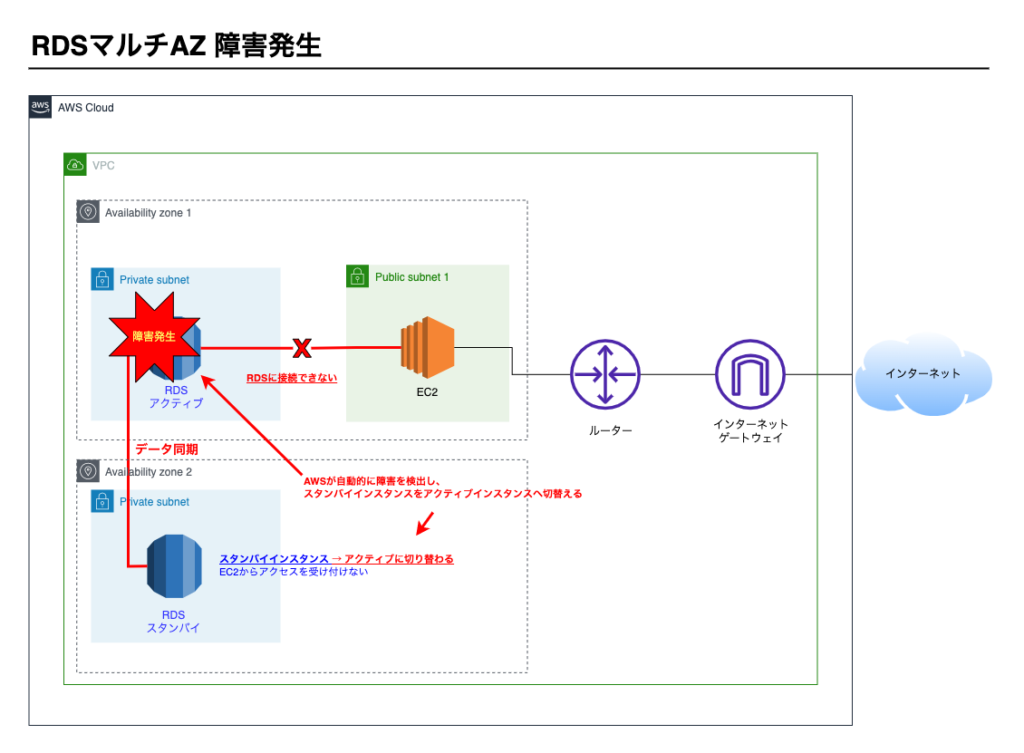
③切り替えが完了し障害復旧
切り替えが終わると、スタンバイインスタンスがアクティブインスタンスとなってEC2からのアクセスを受け付けます。
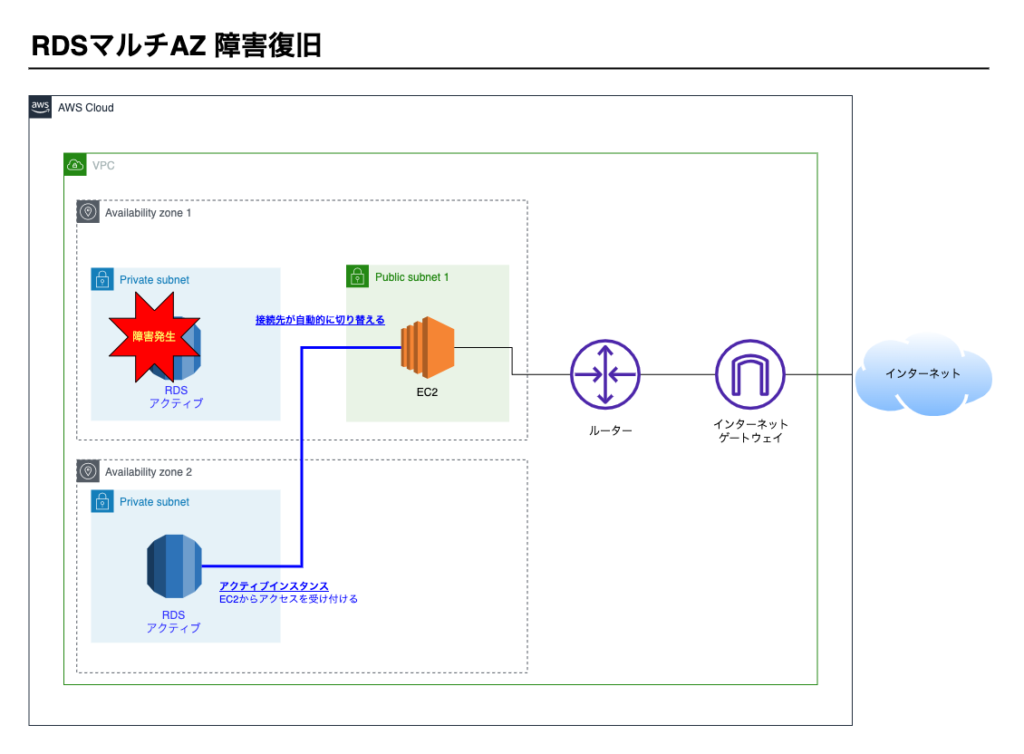
3つの課題の解決
課題1. システムを利用できない時間が発生してしまう。
AWSが障害検知後、自動的にスタンバイインスタンスをアクティブインスタンスに切り替えます。
切り替えには最大60秒要しますが、手動で復旧する時間に比べると十分に短い時間といえます。
課題2. 障害を検知後、マネージメントコンソールを操作するといった手動作業が発生する
自動的にスタンバイインスタンスがアクティブインスタンスに切り替わるため手作業は不要
課題3. データやファイルを失う可能性がある。
データは同期されるため失われない
これにてRDSの耐久性が確保できました。
以上で、本パートは終了です。お疲れ様でした。
次のパートでは、筆者の考えをコラムとして紹介します。前のパートに戻る完了して次のパートに進む
6-4
コラム: 大規模障害の対策
6-1で大規模障害の例を挙げましたが、対策方法を2つご紹介します。
なお、大規模障害は発生頻度も稀であり、実際の構成も複雑になるため概念のみの解説とします。
- マルチAZの構成にする
- マルチリージョンの構成にする
マルチAZの構成にする
1つのAZが機能しなくなってもシステムが停止しない構成にします。
6-1で挙げた2019年8月23日に東京リージョンの大規模障害は1つのAZで障害が起きたため、マルチAZの構成にしていれば回避できた可能性があります。
マルチリージョンの構成にする
1つのリージョンが機能しなくなってもシステムが停止しない構成にします。
マルチリージョンの構成にしておけばサービスが停止することはほぼ無いといって良いでしょう。
高い可用性が得られる反面、マルチリージョンの構成は複雑ですので構築し検証する工数も必要です。AWSの運用コストも上がります。
サービスが停止することで、社会に影響があるサービスの場合、マルチリージョン構成を採用すると言ってよいでしょう。
以上です。お疲れ様でした。
次のパートでも、筆者の考えをコラムとして紹介します。
6-5
コラム: カオスエンジニアリングについて
カオスエンジニアリングというテスト手法がありますのでご紹介します。
カオスエンジニアリングとは
カオスエンジニアリングとは、意図的に障害を発生させシステム全体が停止しないことを確認するテストです。
具体的には次のような障害を意図的に発生させます。
- インスタンスを強制的に停止する
- 1つのAZ上で稼働させているサービスを強制的にすべて停止する
- 1つのリージョン上で稼働させているサービスを強制的にすべて停止する
Chaos MonkeyとChaos Kong
動画配信サービス大手のNetflix社はChaos Monkeyというツールを開発し、ランダムでサーバーをダウンさせるというシミュレーションを2012年頃から行っていたそうです。
さらに、リージョンまるごとダウンさせるやChaos Kongという上位ツールも開発しシミューレートしているそうです。
まさに、Design for Failure(障害が発生することを前提にシステム設計を行うという考え方)を具体化したアプローチです。
AWS Fault Injection Simulator
AWSも2021年、カオスエンジニアリングのサービスを開始しました。
本教材では触れませんがカオスエンジニアリングサービスがあることをご紹介します。
今後はカオスエンジニアリングで可用性・耐久性を確保することが一般的になることでしょう。
以上で、本章は終了です。お疲れ様でした。前のパートに戻る最後のパートを完了する
